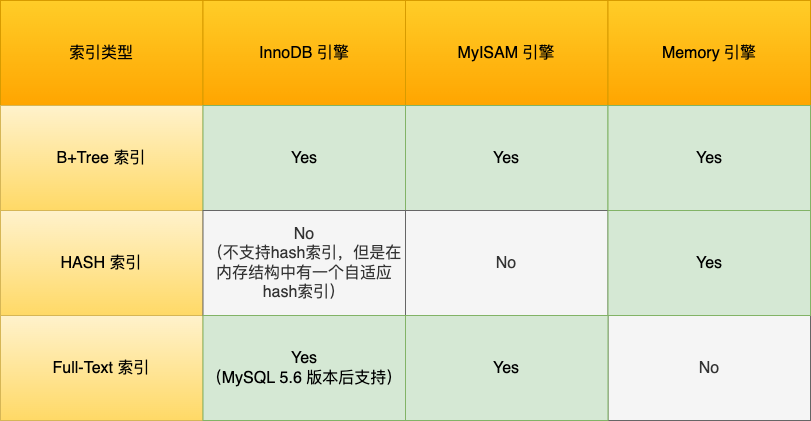
介绍
类似书的目录一样对数据进行分类,加快数据查找速度。
分类
- 按数据结构分类
- 按物理存储分类
- 按字段特性分类
- 按字段个数分类
数据结构分类
InnoDB选择索引的方式
- 有主键
- 无主键,全有效列
- 都没有,隐式自增id
B+树
多叉树,叶子结点存放数据,非叶子结点存放索引
每个结点按主键顺序存放,非叶子结点,则用来划分区域
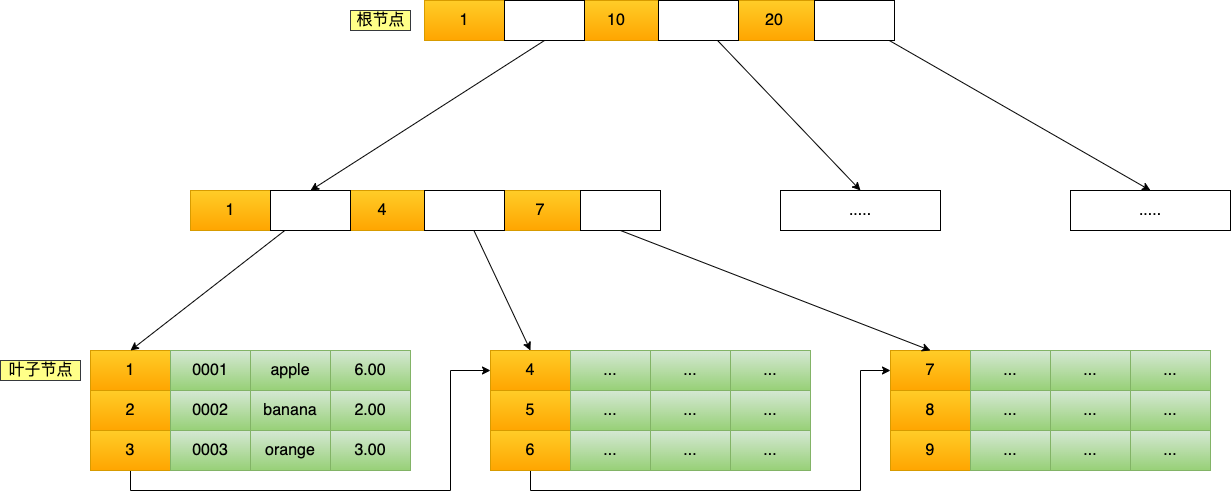
存储千万级的数据最多需要 3-4 次磁盘IO ???
对于二级索引
叶子结点只存储主键值。
使用二级索引查询后,需要再查一次主键的 B+树,称作【回表】
如果只查询二级索引树存储的值,如主键,就能直接返回结果——【覆盖索引】
对比B+树、B树、二叉树、哈希的区别
- B树非叶子结点也要存数据,而是是单链表;空间消耗大,无法查询范围。
- 二叉树只能存两个子结点,高度相比多叉树会高出很多。
- hash无法做范围查询
物理存储分类
主键和二级索引的叶子结点存储结构不同
字段特性分类
主键索引:即以主键为索引
唯一索引:以唯一 UNIQUE 字段为索引,允许空值
普通索引:以普通的字段为索引
前缀索引:以字符类型的字段的前几个字符建立索引,可以减少索引占用的存储空间。
字段个数分类
单列索引
联合索引(多列、复合索引)
需要遵循最左匹配原则,where从左边开始匹配,顺序打乱索引会失效。
进行到范围查询时,之后的字段会失效。
key_len 记录使用了多少个
>, >=, BETWEEN...AND..., like j%
索引下推
Extra: using index condition
索引区分度
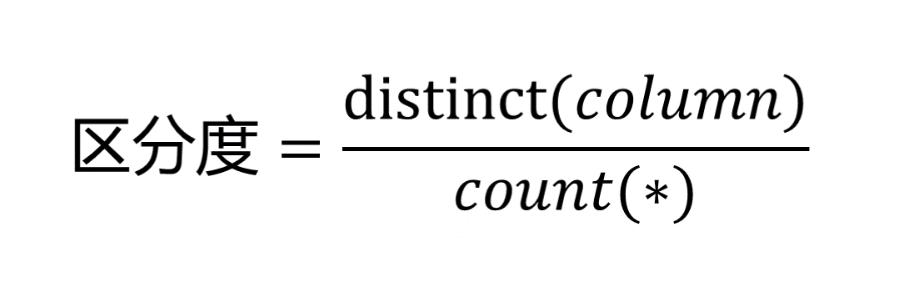
性别就很小,不适合放在前面
查询优化器:全表扫描
什么时候需要、不需要索引?
缺点:
- 空间消耗
- 维护耗时
适用场景:
- 唯一性限制
- 经常条件查询的
- 经常 group by 和 order by 的,无需二次排序。
不适用场景:
适用场景反例
经常需要修改的字段
优化方式:
前缀索引优化
覆盖索引优化
自增索引,减少树结构的维护时间
页分裂问题
非 NULL
防止索引失效
- 左边、左右模糊匹配
- 对索引列进行计算
- 联合索引违背最左原则
- OR两边有一边不是索引列
可以通过 explain 的 key查看实际用的索引、key_len 查看生效的索引长度、type查看扫描类型
EXPLAIN type 介绍
- All 全表扫描
- Index 全索引扫描,只返回索引列
- Range 索引范围扫描
- ref 非唯一索引扫描
- eq_ref 唯一索引扫描,通常发生在基于唯一索引的连表查询(相等的)
- const 结果只有一条的唯一主键或唯一索引扫描
extra
- using filesort
- using temporary
- using index 覆盖索引