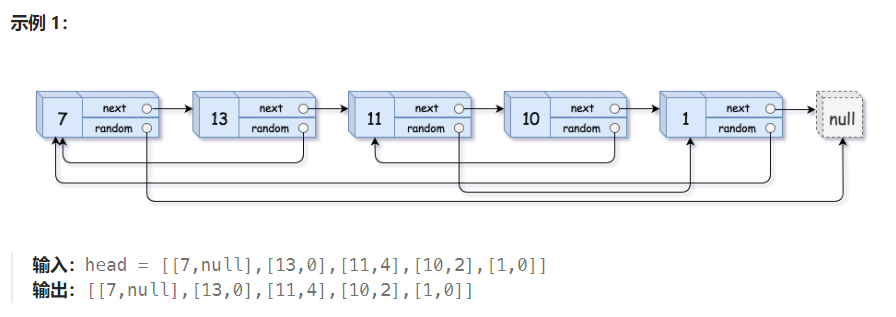
树的名词 二叉树 红黑树 布隆过滤器 随机链表的复制
复制链表,可以通过建立一个头节点,一个一个节点新建然后再串起来。
但是 random 怎么串?它引用的节点可能此时还没创建(如图 11 -> 1)
怎么在还没创建的情况下,获得拷贝后链表的 random 映射关系?
借助【旧链表】的 random 关系来找到【新的节点】,然后连接。
也就是说,我在通过 random 索引到【旧链表】的某个节点时,能够获得这个节点对应的拷贝后的节点。
所以,可以先一次遍历通过【哈希表】在创建新节点的同时,记录【新:旧】节点的这样一个关系。
然后再从头遍历,通过旧节点映射到新节点,分别连接 next 和 random,直至结束。
解题代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 class Solution { public Node copyRandomList (Node head) { if (head == null ) return head; HashMap<Node, Node> map = new HashMap <>(); Node cur = head; while (cur != null ){ map.put(cur, new Node (cur.val)); cur = cur.next; } cur = head; Node dummyHead = new Node (0 ), tail = dummyHead; while (cur != null ){ Node copy = map.get(cur); copy.random = map.get(cur.random); tail.next = copy; tail = tail.next; cur = cur.next; } return dummyHead.next; } }
合并 K 个升序链表
由于链表本身有序,借助两个有序链表合并的思路,可以新开一条链表 ans,数组中每一条链表依次合并进去。
时间复杂度分析:假设每个链表的最长长度是 n。第一次合并 ans 长度为 n,第二次为 2 x n,第 i 次是 i x n,数组总共有 k 组,总共就是 k 次,总时间为 O(k^2^n) 近似 O(n^3^)
经过分析,发现在一组一组的比较中,开头部分一直重复比较浪费时间,
而每个链表都是有序的,因此可以借助【优先队列】先有序存储每一组的链表的头节点,“一层一层”排序,
每次出队加入 ans 中,如果还有后继节点继续加入其中,保证每个节点只访问一次。
时间:总数 kn 个,堆排序时间 logk,总时间 O(kn x logk)。
解题代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class Solution { public ListNode mergeKLists (ListNode[] lists) { int n = lists.length; PriorityQueue<ListNode> pq = new PriorityQueue <>(Comparator.comparingInt(b -> b.val)); for (ListNode p: lists){ if (p != null ) pq.offer(p); } ListNode dummy = new ListNode (), cur = dummy; while (!pq.isEmpty()){ cur.next = pq.poll(); cur = cur.next; if (cur.next != null ){ pq.offer(cur.next); } } return dummy.next; } }
LRU 缓存 LRU是Least Recently Used的缩写,即最近最少使用。
当容量满的时候,需淘汰 LRU 元素。
【在 Java 中,LinkedHashMap 就遵循了该规则】
什么是 LinkedHashMap ?
答:在做到哈希表的同时,能够记录每个节点(键值对)相对的位置。
O(1) 的获取必然要用到哈希表。
如果超出容量就要移出最久未使用的,就必然要根据每次 get 和 put 保留操作元素的记录,然后得到最久未用的。
乍一看,可以用队列来存储操作记录,先入队的表示之前使用的,后入队的表示现在使用的;
这样的话,当溢出时,直接出队然后移除哈希表中的值就可以了?
但是存在: 1 2 3 2 这一种情况,即最新操作的节点记录在之前仍然存在,就会出现【误删】最新的节点。
所以在插入前,应该遍历队列删除这个 key,然后保留最新记录。
【但是这样违背了 put 操作 O(1) 的时间规定】
因此,可以将哈希表和双链表结合起来!
哈希表存储 key 对应的节点,做到元素 O(1) 的删除(先哈希索引,然后删除),需要自己实现链表的删除方法;
然后双链表充当队列,头部记录最新的操作节点,随着节点增加,尾部就作为【最久未使用】的节点了。
至此保证了 put 和 get 的 O(1) 时间。
put 也算一次操作哦,需要更新最新操作节点记录。
解题代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 class LRUCache { class DNode { int key; int value; DNode pre; DNode next; public DNode () {} public DNode (int _key, int _value) {key = _key; value = _value;} } HashMap<Integer, DNode> map = new HashMap <>(); DNode head, tail; int capacity; public LRUCache (int capacity) { this .capacity = capacity; head = new DNode (); tail = new DNode (); head.next = tail; tail.pre = head; } public int get (int key) { DNode node = map.get(key); if (node == null ) return -1 ; moveToHead(node); return node.value; } public void put (int key, int value) { DNode p = map.get(key); if (p != null ){ p.value = value; moveToHead(p); } else { DNode node = new DNode (key, value); map.put(key, node); addToHead(node); if (map.size() > this .capacity){ DNode r = removeTail(); map.remove(r.key); } } } public void addToHead (DNode node) { node.pre = head; node.next = head.next; head.next.pre = node; head.next = node; } public DNode removeNode (DNode node) { node.pre.next = node.next; node.next.pre = node.pre; return node; } public void moveToHead (DNode node) { removeNode(node); addToHead(node); } public DNode removeTail () { return removeNode(tail.pre); } }