区别于“数据处理函数”:
分组函数是多行函数,多行数据产生一个结果 (如果没有 group by)
没加 group by 即一整张表就是一组。
数据处理函数是单行函数,一行数据一个结果。
分组函数
分组函数共有:max, min, avg, count, sum。
常见问题
Q: count(*) 和count(字段) 的区别?`
A: 前者是统计所有字段不全为 NULL 的数量,即整张表的行数;后者是统计该字段不为空的个数。
Q: 分组函数不能使用在 where 条件中
A: 因为分组函数是根据查询结果计算的,如果加在 where 中就会不断改变,无法计算。
注:多行函数是自动忽略 NULL 的,因为是从所有行中统计出结果。
group by
将查询结果按照某个字段分组,或者多个字段联合分组,在 where 后执行。
经过分组后 sql 语句,只能 select 分组函数和分组字段
因为分组后,其他数据“糅合”在一起了,无法正常显示。
having
在分组后,对分组数据进行筛选。
分组数据:分组函数产生的数据,或分组字段。
建议只有涉及到分组数据的筛选采用 having,其他用 where 提前过滤掉,保证查询效率。
区别举例:查询部门为 job 的平均薪资数据
1 | # 低效用法 |
组内排序
substring_index
按分隔符分割。
语法格式:
substring_index(字符串, 分隔符, 子串数量)
group_concat
将分组后的同组数据进行拼接。
语法格式:
group_concat(字段 [order by ...]) 可选是否排序
注意:和 group by 后的 select 语句相反,这里不应该出现分组函数和分组字段,因为同组的数据结果相同。
但是 MySQL 是允许的。
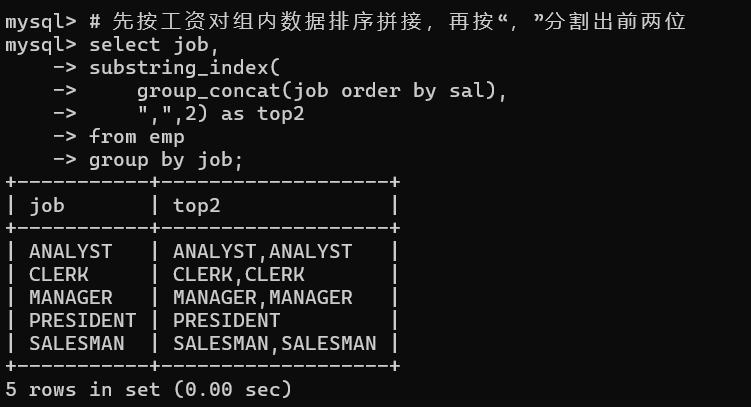
联合使用举例:找出每个工作岗位的工资排名在前两名的员工姓名。
1 | # 先按工资对组内数据排序拼接,再按“,”分割出前两位 |
语句执行顺序
一个相对完整的 sql 语句的执行顺序如下:
1 | select ... # 5 |
可以参考这个顺序对 sql 语句进行优化。