介绍
特点
- Java是基于jvm虚拟机运行的跨平台语言
- 内置垃圾收集,不用考虑内存管理
JRE 和 JDK 介绍
JRE: 用于运行 被编译为字节码class 的 Java 代码
JDK:提供编译器,调试器等用于编写 Java 代码工具
JRE: Java Runtime Environment
JDK: Java Development Kit
命令行常用命令
- Java: 启动jvm虚拟机,运行编译为class字节码的代码。
- Javac: 编译Java代码
- Javadoc: 注释文档
- jdb: 调试器
JDK与JRE的关系
JDK = JRE + 开发工具(Javac.exe等)
JRE = JVM + Java API
开发程序,需要用到JDk,因为要用Javac编译.Java文件
运行程序,只需要用到JRE,包含了Java API
名词介绍
- JSR规范: Java Specification Request
- JCP组织: Java Community Process
JSR规范用于保证 Java 语言的规范性。
凡是想给 Java 平台添加一个功能,比如说访问数据库的功能,需要先创建一个 JSR规范,定义好接口。
各个数据库平台必须按照规范实现该接口,开发者就用同样的API访问各个数据库平台。
- RI: Reference Implementation
- TCK: Technology Compability Kit
- IDE: Integrated Development Environment
语法规则
命名规则
- 变量、类名 必须以英文字母开头,后接字母,数字和下划线的组合
- **类名 **习惯首字母大写
- 如果单个源文件中有多个类,那么只能有一个类是public类,表示该文件的主入口
在java编程思想(第四版)一书中有这样3段话(6.4 类的访问权限):
每个编译单元(文件)都只能有一个public类,使得每个编译单元都有单一的公共接口,用public类来表现。该接口可以按要求包含众多的 支持包访问权限 的类。
如果在某个编译单元内有一个以上的public类,就不知道使用哪个类导致无法编译。
同时允许编译单元内完全不带public类,这时候可能会并入其他编译单元编译,并且启动该文件时需手动指定数据来源(文件内存在的多个class)
- 源文件的名字必须与 public 类的类名相同
- 如果源文件中没有 public 类,则文件名可以是任意的
Hello world分析
1 | public class Hello { |
- main方法必须声明为静态方法,作为程序执行入口
- 在书写完Java文件后,使用Javac命令编译源文件
javac -encoding=utf-8 Hello.java
如果文件编码非utf-8需使用encoding选项指定编码格式
- 运行代码
1 | java Hello # 不需要带.class扩展名 |
主类
Java程序的执行入口是main方法,==包含有main方法的类称为主类==
- 一个Java源文件中可以有零个或多个主类。
假如一个Java文件中有3个类,则在编译后会生成3个class文件
只有包含main方法的主类才能使用Java命令运行
- 如果程序中包含主类,则称为Java应用程序。没有就叫做Java库程序,通常被用来让其他Java程序调用.
反编译
从源代码到可执行代码,称为编译,也称为正向工程。
从可执行代码到源代码,称为反编译,也称为逆向工程。
可用 javap命令实现反编译。
但并没有实现完全的反编译,只反编译到方法声明这一层,无法反编译方法内的代码。
注释
- //… 单行注释
- /* … */ 多行注释
- /** … */ 文档注释
数据类型
- 整数类型:byte,short,int,long
- 浮点数类型:float,double
- 字符类型:char
- 布尔类型: boolean
只有 true 和 false 两个值。
Java语言对布尔类型的存储并没有做规定。
理论上存储布尔类型只需要1 bit,但是通常 JVM 内部会把boolean表示为4字节整数==。
- 引用类型,类似如C语言的指针。
在Java中,对象的实例化变量常为引用类型
常量,使用final关键字声明。
var关键字
当类型名太长可以用var来进行声明,编译器会根据赋值语句来自动推断出该变量的类型
1
var s = new StringBuilder();
特殊规则
- Java只定义了带符号的整型,即最高位为符号位。如,int 最大值为 2^31-1
- 支持使用 _ 来连接数字,结果和原数一致。
1 | int x = 2_000; |
- 0前缀表示八进制
- 0x前缀表示十六进制
- 0b前缀表示二进制
- long类型需在数字后加上字母大小写 “L”
- 定义float类型变量时末尾一定要加上字母大小写”F”,因为默认浮点数为双精度(double)类型
运算
运算符
/除法运算符%求余运算符>>右移运算符,无法移动符号位,即负数右移后还是负数>>>可以移动符号位的右移运算符<<左移运算符同理,不存在向左移动符号位的运算符。对
byte和short类型进行移位时,会首先转换为int再进行位移。++,--自增自减运算符只能用于 整型 和 浮点型 变量。instanceof运算符,判断前者是否为后者的实例化对象。1
2Integer a = 2;
a instanceof Integer; //得到true位运算:
&,|,~,^分别是与,或,非,异或运算。逻辑运算符:
&&,||,!的操作元必须是boolean型数据。
整数运算
- 两个整数相除只能得到结果的整数部分(即舍弃余数得到整数)
- 整数的除法对于除数为0时运行时将报错,但编译不会报错。
溢出:
整数由于存在范围限制,如果计算结果超出了范围,就会产生溢出,而溢出不会出错,却会得到一个奇怪的结果。(占据符号位,成为负数)
浮点数运算
浮点数比较正确做法
1 | double r = Math.abs(x - y); // 取绝对值 |
注意:
在一个复杂的四则运算中,两个整数的运算不会出现自动提升的情况。
1 | double d = 1.2 + 24 / 5; // d = 1.2 + 4 |
原因:类型提升指的是最后赋值的时候,而算式中 24 / 5 依然遵循整数运算规则。
溢出:
整数运算在除数为0时会报错,而浮点数运算在除数为0时,不会报错,但会返回几个特殊值:
NaN表示Not a NumberInfinity表示无穷大-Infinity表示负无穷大
布尔运算
短路运算:如果一个布尔运算的表达式能提前确定结果,则后续的计算不再执行,直接返回结果。
运算精度
- 如果表达式中最高精度低于Int型整数,则按int精度计算
如 ‘a’ + ‘b’ = int型数字
byte x=7; 则执行表达式 ‘B’+x; 的结果是int型。
- char型数据和整型数据运算结果的精度是int精度
- Java允许把不超出取值范围的算术表达式赋值给对应类型,但是当算术表达式中含有变量的时候,只会检查变量的类型
1 | int z = 1; |
类型遵循自动==小转大==,不支持==大转小==(可以强制转型)
强制转型:超出范围的强制转型会得到错误的结果
如 int -> short:int的两个高位字节直接被扔掉,仅保留了低位的两个字节
- 较小类型和较大类型运算,结果会自动转化为较大类型。
字符
Java 在内存中总是使用 Unicode 表示字符。
所以 char 类型占用两个字节。
可以用转义字符 \u + Unicode编码(十六进制)表示一个字符
1 | // 注意是十六进制: |
字符串
转义字符
\"表示字符"\'表示字符'\\表示字符\\n表示换行符\r表示回车符\t表示Tab\u####表示一个Unicode编码的字符
不可变特性
字符串的内容是常量,不可改变,无法通过索引元素改变其值。
1 | // 字符串变了吗? |
字符串变量为引用类型
对其再次赋值,仅仅改变其指向的内存,原内容依旧存在。
功能
可以使用 “+” 连接字符串
也可以用 “+” 连接字符串和其他数据类型,结果为字符串类型,被拼接的其他数据类型自身不会改变。
‘’’ … ‘’’ 三引号用于表示多行字符串,Java 13 以后
1
2
3
4
5
6String s = """
...........SELECT * FROM
........... users
...........WHERE id > 100
...........ORDER BY name DESC
...........""";解释:字符串s占据==5行==,因为在desc后面还有一个’\n’,如果不想要5行,可以直接把三引号写在结尾
排版:最后会根据每行字符的相对位置来显示,共同的空格会被忽略,不规则排版则是以最短的空格为基准。
null 与 “” 的区别
null:一个引用空值。
“”:一个空的字符串,并不是空值。
== 在引用的使用
1 | String a = "hello"; |
原因是:== 用于判断两者是否为同一个引用,而不是判断内容是否一致。
判断字符串内容相等可以使用String类型的equals方法
1 | a.equals(b) |
低内存的特殊
对于数值占用内存较少的情况,JVM 为了节省内存空间,在创建不同变量的时候指向的内存地址都是一样的。
如在128以内(不包括128)的数字
当有多个引用指向它们时,地址是一样的
1 | Integer a = 1; |
数组
Java 中为了保存 C 语言开发的习惯,保留了int arr[] 和 int[] arr 声明数组类型的形式。
初始化
new关键字
1
int[] arr = new int[]{1,2,3};
可以把
int[]看做一整个数组类,new 出一个 int[] 的对象。数组常量
1
int[] arr = {1,2,3};
数组常量只能用于初始化,不能声明再赋值。
特点
int[] 括号内不需要指定数字,在初始化的时候会自动推断。
1
2// {}内指定了数组元素,这里的3可以省略
int[] arr = new int[3]{1,2,3}如果没有指定,也没有指定数字(数组长度),那这个数组长度只有就是0。
1
2// 声明一个长度为 10 的数组,默认值为 0
int[] arr = new int[10];初始化后,数组的长度将不可改变,超出长度的索引会报异常。
创建的数组元素,如果没有赋予初值,会被赋予默认值
数值型基本数据类型的默认值是 0
char 类型的默认值为 ‘\u0000’
boolean 类型默认值为 false。
通过访问 length 属性可以获得数组的长度。
注意:
1 | import java.util.Arrays; |
names[1] 是一个元素,不是引用。
多维数组
初始化
1 | int[][] ns = { |
打印多维数组
打印多维数组可以使用Arrays.deepToString();
排序数组
使用 Arrays 类的成员函数sort,可对数组进行排序
默认小到大排列: Arrays.sort(arr);
逆序: Arrays.sort(arr,Collections.reverseOrder())
sort 不能直接用于排列多维数组,==使用什么可以排序多维数组呢==
多维数组不需要排序,本质是处理每个一维数组。
应用
- 使用 Scanner 类初始化数组
1 | Scanner scanner = new Scanner(System.in); |
- 随机打乱
1 | import java.util.Arrays; |
注:使用传递==数组引用==的方式才能在 不同作用域 交换数组内的值
1 | class Swap { |
复制数组
使用Java.util.Arrays的静态方法copyOf复制数组
1
newArr = Arrays.copyOf(oldArr,neededLength);
使用System类中的静态方法arraycopy
使用clone方法复制数组
for each循环
对于可迭代对象,使用for循环的”for each”形式会显得更加简洁
形式: for( varName : arrayName) {…}
1
2
3
4
5
6
7
8public class Test {
public static void main(String[] args){
int[] arr = new int[] {1,2,3,4,5};
for(int n: arr){
System.out.println(n);
}
}
}这里的n,代表数组中的每个元素,而不是索引值
使用该方法遍历数组,无法控制访问顺序
for each循环还可用于List,Map等数据结构
转 Stream 流
1
Arrays.stream(arr)
命令行参数
在使用 java 命令执行 java 文件的时候
可以传入 …String 类型的参数,由 public 类的入口函数 main 的 args 参数获取
1 | java Main "123" "456" |
流程控制
输入
通常使用Scanner类的实例对象来接受用户输入
Scanner 类包含在 java.util 包内,需要先引入
1 | import java.util.Scanner; |
注意
nextInt 表示获取用户的下一个输入并转化为 int 类型,不是从输入中获取下一个 int 类型
1 | 用户输入 |
输出
使用System.out输出流向输出端输出数据
- System.out.println() 输出一行
- System.out.print() 直接输出
- System.out.printf() 格式化输出
格式字符:
%d 输出整型数据
%c 输出字符型数据
%f 输出浮点型数据
使用如%m.nd形式,可以控制输出的排版。
m:数字所占位数
n:小数位数
注意:因为 % 表示占位符,所以连续两个 %% 才表示一个 % 字符本身。
if判断
if 中表达式必须是 ==boolean类型==,不能使用 0,1,null 代替
switch新用法
switch 中 case 的条件必须是常量,枚举也可以。
Java 12 开始,使用 -> 符号可以无需break,直接指定执行单一路径,而不会继续向下执行其他语句
switch 将返回被执行 case 条件的结果
1 | public class Test { |
如果需要使用复杂的语句,可以使用花括号{}包裹,再通过yield关键字返回值
1 | case "mango" -> { |
从 Java 13 开始允许使用yield返回值
循环
while
while循环中的判断条件必须是一个 boolean 值,如 3 > 2 的结果,而不能直接放一个数字
1 | public class Test { |
对于循环条件判断,以及自增变量的处理,要特别注意边界条件。思考一下下面的代码为何没有获得正确结果:
1 | public class Main { |
n的边界是 0 -> 100,当 n = 100 时,会再次进入循环,n 变成了 101。
导致结果多加了一个 101,原本为 5050
将这个操作改为 for 循环则不会有这个问题,因为 自增变量 始终作为后置条件在循环体内执行完之后。
do while
改写 while 循环的 1 到 100 求和
1 | public class Main { |
for
改写 1 到 100 求和
1 | public class Main { |
计数器定义位置
如果变量 i 定义在 for 循环外:
1 | int[] ns = { 1, 4, 9, 16, 25 }; |
破坏了变量应该把访问范围缩到最小的原则。
for each
1 | public class Main { |
和for循环相比,for each循环的变量n不再是计数器,而是直接对应到数组的每个元素。
除了数组外,for each循环能够遍历所有“可迭代”的数据类型,包括后面会介绍的List、Map等。
break 和 continue
break:跳出最近一层循环,多层循环只能跳出一层
continue:跳出本次循环,执行下一个符合条件的循环
面向对象
0. 特点
- 封装性
- 继承
- 多态
1. 字段
字段即成员变量
没有初始化的引用字段,默认为null值; 其他类型的也是默认值,如Int类型是0,boolean是false;
静态方法
- 静态方法可以通过对应类的空对象访问
1 | class Test { |
注意:
- 在==成员函数内部==声明的局部变量不会自动初始化,需要初始化后才可引用
- 无论成员变量,和成员函数声明定义的顺序如何,==成员变量是先与成员函数生成的==,所以可以出现以下这种情况
1 | class Test { |
- 不能在成员函数中定义与参数重名的变量
- 可以在成员函数中定义与成员变量同名的变量,定义的局部变量会覆盖成员变量。
2. 构造函数
构造函数支持重载(Overload)
Java中可以通过this引用可以在一个构造函数中调用其他构造函数,但是C++不行,因为可以有默认参数, 所以就没有构造函数的相互调用了,但是C++可以调用父类的构造函数
3. this关键字
- this是Java的一个关键字,表示某个对象
- 在构造方法中,代表该构造方法所创建的对象。
- 实例方法中,代表正在调用该方法的当前对象。
- this不能用于类成员变量和类方法。
- 可用this调用被隐藏的成员变量
如:当局部变量和成员变量重名时,可以使用this.成员变量访问到它
4. 包
包是一种用来管理类的机制,可以有效地区分名字相同的类
使用方法:
- 用package 包名;语句声明该源文件所在的包
注意事项:
- 该语句必须作为源文件的第一行语句。
- 建议用域名反写的方式建包(目前还没有看懂)。
- 包的名字,必须为源文件所在路径,不能随意起名。
如tom/jiafei/路径下有Test.Java文件,则该文件的包名可以为tom.jiafei
运行方式:
如果主类的包名是tom.jiafei,就必须到tom\jiafei的上一层(即tom的父目录)目录中去运行主类。
假设tom\jiafei的上一层目录是1000,那么必须用如下格式来运行: C:\1000> Java tom.jiafei.主类名
import语句
既然有包的建立,那必然有引用包。
系统会自动导入Java.lang包中所有的类。
通过import语句,可以使该源文件能够调用其他包中的类。
==父包和子包没有关系,包含的类也没有关系==
5. 修饰符
Java使用四种修饰符,来限制类中的成员变量和成员函数被访问的权限
- public类。 该类成员可以被所有类访问
- protected类。 该类成员只能被同一文件,同一包内的类或子类访问。
- 没有修饰符的称为default类。 只能被同一文件,和同一包内的类访问。
子类不能访问指:其他包通过引用该包,然后继承该包中的某一个类,该子类无法访问父类的成员。
==事实证明即使是default类,只要其子类在同一个文件或包,依旧能够访问父类成员。==
- private类。 该类成员只能被自己访问。
6. 包装类
为了方便基本数据类型的使用,Java提供了基本数据类型的相关类,实现了对其的封装。
如:Integer,Character,Byte等类。
构造方法如:Integer a = new Integer(2);
返回类中包含的值:a.value();
7. 上转型对象
将子类的对象传递给父类引用,称为上转型对象。
如:
1 | Father f = new Son(); |
使用:
- 不可以使用子类新增的成员(变量、函数)
- 可以使用子类继承和重写的方法
- 可以使用子类隐藏的成员变量
如:父类有int a变量,而子类定义了同名变量double a,而上转型对象调用的是父类的a变量。
==不支持向下转型,会报出ClassCastException==
多态
多态就是指父类的某个方法被子类重写后产生自己的功能行为,各个子类都不同。
8. 抽象类
用于定义共有的属性(变量、方法),合理地使用抽象类,可以写出易维护、易扩展的程序。
==抽象类可以没有abstract方法==
==不可以使用static修饰抽象类==,因为抽象类没有实例吧。
使用:
- 具备一般类的基本能力,可以有字段、构造方法;但不能实例化abstract类对象
- 不能用final修饰抽象类,因为定义抽象类就是要用来继承的。
- 抽象类的非抽象子类必须实现抽象父类的所有抽象方法。
缺点:==Java中只能继承一个类,所以抽象类并不完善==
9. 接口
为了弥补只能继承一个类的缺陷,Java定义了接口概念。
接口和抽象类差不多,但是比抽象类更加标准化。接口还有一个优势:==允许非同一父类的子类拥有相同名称的方法。==
使用:
通过interface 接口名{},与定义一个类差不多的形式定义接口;
- 接口中不存在变量。==声明常量时必须初始化,不具有默认值==
类似int MAX = 100;
等价于:(public static final) int MAX = 100; 括号内为缺省类型,即可以省略不写。
- 接口中所有的方法默认都是抽象方法
如void f(); => 等价于 public abstract void f() {};
- 可以用default关键字定义实例方法(JDK8后),必须是public方法,可省略不写。
default方法与普通类的实例方法一致,该接口的实现类可以选择是否重写,重写需去掉default关键字。
- 允许使用static关键字定义静态方法(JDK8后)
- 允许使用private关键字定义私有方法,接口的实现类无法访问private方法,目的是配合default方法使用实现一些算法的封装。(JDK9)
注意:
- 接口没有构造函数
- 所有字段除了private, 其他的访问权限都是public
实现接口
通过implements关键字可以实现一个或多个接口,接口之间用逗号隔开。
- 非抽象类实现接口,必须重写所有抽象方法。
- 接口的实现了不拥有接口的静态和私有方法。
- 实现接口方法的访问权限必须是public, 允许重载接口方法,并修改访问权限
如接口有void cry(); 子类可以定义protected void cry(int m)方法。
接口回调
将接口的实现类对象的引用赋值给接口变量,再通过接口变量调用实现类实现的方法,称为接口回调。
实际过程是:在接口变量调用方法时,根据地址通知对应的对象去调用对应的方法。
接口与抽象类的比较
- 接口和abstract类的比较如下:
- abstract类和接口都可以有abstract方法。
- 接口中只可以有常量,不能有变量;而abstract类中即可以有常量也可以有变量。
- abstract类中也可以有非abstract方法,接口不可以(JDK 7及以前的版本)。
10. Lambada表达式(JDK8后)
Lambada表达式,又称为匿名表达式;常用在单接口(只具有一个abstract方法的接口)的接口回调中。
形式:(参数列表) -> {方法体}
Lambada表达式的值就是该方法的入口地址,可以将其赋给接口变量来实现单接口,用于接口回调。
1 | interface A { |
11. 内部类
在一个类中,再定义一个类,那么该类就叫做内部类。
为了代码的易维护,和相关性,可以将需要用到的类写在另一个类中作为内部类。
对于拥有内部类的类,在编译后将生成多个class文件。
使用:
- 外嵌类可以声明内部类对象
- 内部类不能定义静态成员。==为什么内部类可以用static声明==。
12. 匿名类
有时候为了方便可以通过类体直接创建一个子类
- 可以是继承父类的子类
- 也可以是实现接口的子类
- 使用Lambada表达式做到的接口回调也是匿名类。
形式:
new 父类构造方法 / 接口名() {类体}
==匿名类属于内部类==
13. 异常类
用于提供程序运行出现错误的信息,及错误的捕捉
异常对象可以调用如下方法得到/输出异常相关的信息
- public String getMessage();
- public void printStackTrace();
- public String toString();
捕捉异常
Java使用try~catch~finally(可选)来捕捉处理异常,允许存在多条catch语句
==多条catch语句可以分别处理异常,不是匹配一个就结束==
注意:子类异常必须放在父类异常前面,因为父类异常包含子类。
抛出异常
在方法体内使用throw抛出异常对象: throw new Exception();
使用throws声明异常,声明该方法可能会出现的异常
核心类
1. String类
String类不可继承。
String常量:用双引号括起来的字符序列。Java把String常量放在常量池内。
==重点==
- 将一个String常量赋给变量时,如果内容相同的String常量在常量池里已经存在,则不会创建新的字符串常量,而是将已存在的字符串常量引用赋给该变量。
即:String a = “hello”; String b = “hello”;
a == b //输出true
而使用new关键字创建字符串对象,是在堆内申请一份新内存,因此内容相同但不是同一个引用。
String类对象在生成后,无法改变其中的值。
String a = “hello”;
a[1] = ‘a’; // 错误,并且只能通过charAt(index)方法访问。
- 通过+号可以使字符串进行并置运算。
常量并置运算后依旧是常量,而一旦变量参与并置运算,就会重新在堆中创建新的String对象。
与第一点共同思考
String str1 = “helloJava”;
String str2 = “hello” + “Java”;
str1 == str2 // 得到true,运算后依旧是常量
String a = “hello”,b = “Java”;
String c = a + b;
c == str1; // 得到false,因为a,b为String类变量,所以在并置运算后得到新的字符串对象。
与字符数组
可以使用字符数组创建String类对象,也可限制范围;
- String(char a[],int startIndex,int count);
也可以String转字符数组
- public void getChars(int start,int end,char c[],int offset )
- public char[] toCharArray()
与字节数组
String转字节数组
- public byte[] getBytes()。使用平台默认的字符编码。
- public byte[] getBytes(String charsetName)。指定字符编码
==GB2312编码中,一个汉字占两个字节。==
2. 正则表达式
3. Class类与反射
任何类默认有一个public的静态的(static)Class对象,该对象的名字是class(用关键字做了名字,属于Java系统特权),该对象封装当前类的有关信息(即类型的信息),如该类有哪些构造方法,哪些成员变量,哪些方法等。也可以让类的对象调用getClass()方法(从Java.lang.Object类继承的方法)返回这个Class对象:class。
Class对象(class)调用方法可以获取当前类的有关信息,比如,类的名字、类中的方法名称、成员变量的名称等等,这一机制也称为Java反射。
用Class类和反射机制创建新对象(有点问题)
- 使用用Class类的类方法forName(String className)返回对应类的Class对象。
- 再让这个Class对象调用getDeclaredConstructor()方法得到 对应类 的 无参数的构造方法对象。
- 然后构造方法对象再调用newInstance()返回该类的对象
异常处理
通过代码块捕获 异常class类,来知道发生了什么错误,并进行下一步处理。
介绍
类的继承关系如下:
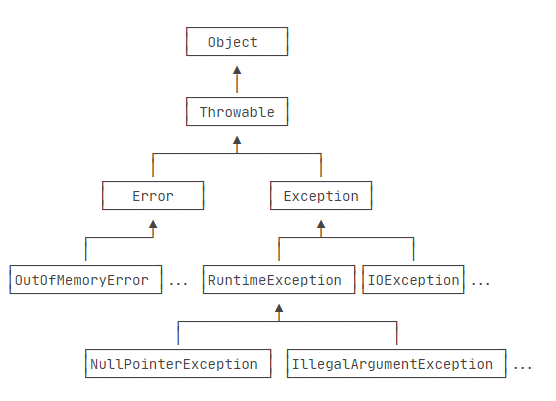
Error表示严重的错误,程序对此一般无能为力
OutOfMemoryError:内存耗尽NoClassDefFoundError:无法加载某个ClassStackOverflowError:栈溢出
而Exception则是运行时的错误,它可以被捕获并处理。
某些异常是应用程序逻辑处理的一部分,应该捕获并处理。例如:
NumberFormatException:数值类型的格式错误FileNotFoundException:未找到文件SocketException:读取网络失败
Java规定(编辑器也会提示):
必须捕获的异常(Checked Exception),包括
Exception及其子类,但不包括RuntimeException及其子类。Checked Exception:需要检查的异常
不包括在内的异常,可以由开发者自由选择是否捕获。
如
NullPointerException,你可以自己选择是否捕获并处理该异常。而
IOException,在 Java 环境中是必须要声明捕获的。不需要捕获的异常,包括
Error及其子类,RuntimeException及其子类。
异常处理建议:异常不应该在产生的代码层级 空捕获不处理,即使真的什么也做不了,也应该把异常记录下来。
1 | static byte[] toGBK(String s) { |
所有异常都可以调用printStackTrace()方法打印异常栈(先进后出)。
因为是栈,所以异常栈最下面才是触发异常的源头。
捕获异常
catch 语句
可以使用多个 catch 语句。
从上到下匹配对应异常类,但是只有一个能被执行。
因此顺序应保持:子类必须写在前面。
因为如果父类(范围大的异常)写在子类前面,就捕获不到子类了,等于没写。
finally 语句
无论异常是否发生,被捕获到,finally中的语句都会被执行。
特点:
- 非必须
- 总是在 try ~ catch 之后,最后被执行
finally 用于保证一些代码必须被执行,防止因为异常跳出了代码原本的运行逻辑。
合并处理异常
每个异常类应该是在不同 bit 位上,因此可以用 | 或运算符联合多个异常。
1 | public static void main(String[] args) { |
完整示例
1 | public static void main(String[] args) { |
抛出异常
异常传播
当某个方法抛出异常后,如果当前方法没有捕获异常,异常就会被抛到上层调用方法,直到被捕获为止。
抛出异常
- 创建某个
Exception的实例 - 用
throw语句抛出
1 | void process2(String s) { |
大部分情况下会合并写成一行
1 | void process2(String s) { |
异常“转换”
1 | void process1(String s) { |
process1在捕获到process2的异常后,抛出了另一个异常 IllegalArgumentException。
那么原异常信息就会丢失,“转换”成了另一个异常暴露给外部
如果想要在抛出新的异常下,同时保留原始的异常信息,就需要把原始异常的实例作为新的异常构建参数传入
1 | static void process1() { |
这样在输出的异常栈信息中,就会包括原始的异常信息。
捕获到异常并再次抛出时,一定要留住原始异常,否则很难定位第一案发现场!
异常屏蔽
finally 与 catch 的执行顺序
finally 语句的内容是一定会执行的,相比于 catch 语句的执行顺序呢?
1 | public class Main { |
执行结果:
1 | catched |
第一行打印了catched,第二行打印了finally。
说明先进入 catch 语句,再执行 finally 语句,并且 catch 中抛出的异常不会影响到 finally 执行
异常屏蔽
如果在执行 finally 语句时抛出异常,那么,catch 语句的异常还能否继续抛出?
答案:catch 中抛出的异常最终会被 finally 中抛出的异常“覆盖”。
本质猜测:
在 JVM 中有一个全局异常处理Handler,在执行目标类中的代码时,虽然 catch 先抛出了异常,但是要等 finally 执行完,handler 中的 catch 才对异常进行捕获,这时候 finally 中抛出的异常也会进入异常栈,覆盖原始异常,类似上述的异常“转换”,从而丢失原来的异常。
catch 中只能抛出一个异常,没有被抛出的异常称为“被屏蔽”的异常(Suppressed Exception)。
如何获取所有的异常信息
方法:先保存原始异常实例,然后调用 Throwable.addSuppressed(),把原始异常添加进来,最后在 finally 抛出。
为什么要在 finally 中抛出?
因为 catch 抛出一条异常就结束了,只能存好这一条异常,留在 finally 中添加了
自定义异常
在项目开发中,为了方便处理不同业务的异常,会自定义异常,以便能精准的捕获。
自定义异常通常继承 RuntimeException。
这一类异常是 JVM 非强制捕获的异常,具有更好的扩展性,并且能自由的空值。
示例:
1 | public class BaseException extends RuntimeException { |
基本都是原样照抄RuntimeException。这样,抛出异常的时候,就可以选择合适的构造方法。通过IDE可以根据父类快速生成子类的构造方法。
真正的目的是区分不同的异常类。
NPE异常
NPE 即 NullPointerException 空指针异常。
避免NPE的好习惯
成员变量在定义时就初始化
1
2
3public class Person {
private String name = "";
}返回空字符串
""、空数组而不是null:1
2
3
4
5
6
7public String[] readLinesFromFile(String file) {
if (getFileSize(file) == 0) {
// 返回空数组而不是null:
return new String[0];
}
...
}Java 8 后,提供了
Optional<T>工具类用于判断1
2
3
4
5
6public Optional<String> readFromFile(String file) {
if (!fileExist(file)) {
return Optional.empty();
}
...
}通过调用 Optional.isPresent() 可以判断结果
定位 NPE
在执行类似如下代码时,Java 默认是不会指出哪个对象是null,只会暴露出目标文件所在行数
1 | a.b.c.x() |
Java 14 以后,只要开启如下 JVM 参数就可以检测出具体的 null 对象。
1 | java -XX:+ShowCodeDetailsInExceptionMessages Main.java |
本质猜测:开启后,每一步对象的嵌套调用都会被记录,当出现错误的时候就显示当前层级,可能会降低性能。
断言
使用 assert 关键字来实现断言。
1 | assert x >= 0 : "x must >= 0"; |
: 冒号后添加可选的断言消息。
如果断言判断失败,会抛出 AssertionError 异常结束程序,并带上断言消息。
断言常用于测试,只要错误就代表测试失败。
JVM 默认关闭断言指令,即遇到assert语句就自动忽略了,不执行。
需要开启 -enableassertions (可简写为-ea)参数启用断言。
1 | java -ea Main.java |
还可以对特定的类启用断言 -ea:com.itranswarp.sample.Main
或者特定的包 -ea:com.itranswarp.sample...,用结尾的 … 表示这是一个包。
日志输出
对比 System.out.println() 有如下好处:
- 可以设置输出样式,避免自己每次都写
"ERROR: " + var; - 可以设置输出级别,禁止某些级别输出。例如,只输出错误日志;
- 可以被重定向到文件,这样可以在程序运行结束后查看日志;
- 可以按包名控制日志级别,只输出某些包打的日志;
- 可以…… 等等
Java 内置了 java.util.logging,可以直接使用。
1 | import java.util.logging.Level; |
输出结果:
1 | Mar 02, 2019 6:32:13 PM Hello main |
可以看出 fine 的日志没有打印出来。
默认日志级别是 INFO,该级别以下的日志不会被打印出来。
JDK 的 Logging 定义了7个日志级别,从严重到普通:
- SEVERE
- WARNING
- INFO
- CONFIG
- FINE
- FINER
- FINEST
局限
Logging 系统在 JVM 启动时读取配置文件并完成初始化,一旦开始运行main()方法,就无法修改配置;
配置不方便,需要在JVM启动时传递参数-Djava.util.logging.config.file=<config-file-name>。
反射
介绍
除了 int 等基本类型外,Java 的其他类型全部都是 class,包括 interface。
JVM也为 int 等基本类型创建了 Class 实例。
而class是由JVM在执行过程中动态加载的。JVM在第一次读取到一种class类型时,将其加载进内存。
没有加载到的class是无法通过Class.forName()找到的。
每加载一种class,JVM就为其创建一个Class类型的实例,并关联起来。注意:这里的Class类型是一个名叫Class的class。它长这样:
1 | public final class Class { |
以String类为例,当JVM加载String类时,它首先读取String.class文件到内存,然后,为String类创建一个Class实例并关联起来:
1 | Class cls = new Class(String); |
每个类的Class实例是唯一的。
每个类的Class实例包含了该class的所有完整信息:

所以可以通过某个类的 Class 实例获取这个类的所有信息,这种操作被称为反射。
动态加载特性
动态加载class的特性对于Java程序非常重要。
利用JVM动态加载class的特性,我们才能在运行期根据条件加载不同的实现类。
例如,Commons Logging总是优先使用Log4j,只有当Log4j不存在时,才使用JDK的logging。
1 | // Commons Logging优先使用Log4j: |
基本使用
如何获取一个类的Class实例
通过类的静态变量class获取
1
Class clz = String.class;
通过类的某个实例的 getClass() 方法获取
1
2String s = "Hello";
Class clz = s.getClass();通过 Class 的静态方法获取
1
2// 参数为类的完整包路径
Class clz = Class.forName("java.lang.String");
对比 instanceof
1 | Integer n = new Integer(123); |
instanceof 不但可以匹配相同类型,还可以匹配该类型的父类
而 Class 实例只能匹配其本身的类型,因为每个 class 都有唯一的 Class 实例。
获取类的基本信息
1 | public class Main { |
数组(例如String[])也是一种类,而且不同于String.class,它的类名是[Ljava.lang.String;。
创建新实例
如果获取到了一个Class实例,我们就可以通过该Class实例来创建对应类型的实例:
1 | // 获取String的Class实例: |
Field
通过类的 Class 实例可以获取到该类的所有实例的字段信息。
获取方法介绍:
- Field getField(name):根据字段名获取某个 public 的field(包括父类)
- Field[] getFields():获取所有 public 的field(包括父类)
- Field getDeclaredField(name):根据字段名获取当前类的某个field(不包括父类)
- Field[] getDeclaredFields():获取当前类的所有field(不包括父类)
getDeclaredField 相比于 getField 更针对自身声明的所有字段(包括private)
Field对象属性介绍
getName():返回字段名称,例如,"name";getType():返回字段类型,也是一个Class实例,例如,String.class;getModifiers():返回字段的修饰符,它是一个int,不同的bit表示不同的含义。
以String类的value字段为例,它的定义是:
1 | public final class String { |
我们用反射获取该字段的信息,代码如下:
1 | Field f = String.class.getDeclaredField("value"); |
获取字段值
f.get(Object) 获取该字段在指定实例的值。
因为每个类只有一个 Class,其中的每个字段只有一个 Field,而类的实例存在多个。
因此要想获取该字段的值,必须指定是哪个实例,所以才要传入实例。
但是不能直接访问非 public 字段,需要声明访问许可。
1 | f.setAccessible(true); |
不声明直接访问 private 字段会抛出 IllegalAccessException 非法访问异常。
setAccessible(true)可能会失败。
如果JVM运行期存在SecurityManager,那么它会根据规则进行检查,有可能阻止setAccessible(true)。
例如,某个SecurityManager可能不允许对java和javax开头的package的类调用setAccessible(true),这样可以保证JVM核心库的安全。
设置字段值
f.set(Object1, Object2) 设置指定实例 Object1 的 Field 字段值为 Object2。
同理,修改非 public 字段,需要声明访问许可。
Method
通过 Class 实例也可以获取该类的所有 method 方法信息。
获取方法(类似Field)
Method getMethod(name, Class...):获取某个public的Method(包括父类)Method[] getMethods():获取所有public的Method(包括父类)Method getDeclaredMethod(name, Class...):获取当前类的某个Method(不包括父类)Method[] getDeclaredMethods():获取当前类的所有Method(不包括父类)
区别:因为方法允许重载,所以在获取 Method 实例时除了需要指定方法名外,还需要显式的按顺序指定参数类型。
Method 实例属性介绍
getName():返回方法名称,例如:"getScore";getReturnType():返回方法返回值类型,也是一个Class实例,例如:String.class;getParameterTypes():返回方法的参数类型,是一个Class数组,例如:{String.class, int.class};getModifiers():返回方法的修饰符,它是一个int,不同的bit表示不同的含义。
调用实例方法
m.invoke(Object, ...params) 调用指定实例的实例方法,类似 Field 的 get 用法。
当我们获取到一个Method对象时,就可以对它进行调用。我们以下面的代码为例:
1 | String s = "Hello world"; |
改写为反射来调用:
1 | public class Main { |
调用静态方法
m.invoke(null, ...params)
由于静态方法是直接绑定到类实例上的,所以第一个参数永远是 null。
调用非 public 方法
也和 Field 类似,需要声明访问许可。
1 | m.setAccessible(true); |
多态
一个Person类定义了hello()方法,并且它的子类Student也覆写了hello()方法
如果从Person类的 Class 获取Method实例,作用于 Student 实例时,调用的是谁的方法。
答案:会调用 Student 的,可能是因为每个 Method 是唯一的,作用于哪个实例,就是哪个实例的方法。
因此,使用反射调用方法时,仍然遵循多态原则:即总是调用实际类型的覆写方法(如果存在)。上述的反射代码:
1 | Method m = Person.class.getMethod("hello"); |
实际上相当于:
1 | Person p = new Student(); |
Constructor
通常使用new操作符创建新的实例:
1 | Person p = new Person(); |
如果通过反射来创建新的实例,可以调用Class提供的newInstance()方法:
1 | Person p = Person.class.newInstance(); |
直接调用 newInstance() 方法只能调用该类的public无参数构造方法。
如果构造方法带有参数,或者不是public,就无法直接通过Class.newInstance()来调用。
因此,Java提供了这个类似Field、Method的Constructor类,包含了一个 Class 的所有构造方法信息。
属性相关
getName():返回方法名称,例如:"getScore";getParameterTypes():返回方法的参数类型,是一个Class数组,例如:{String.class, int.class};
获取方法
getConstructor(Class...):获取某个public的Constructor;getConstructors():获取所有public的Constructor;getDeclaredConstructor(Class...):获取某个Constructor;getDeclaredConstructors():获取所有Constructor。
使用
1 | public class Main { |
同样,调用非public的Constructor时,必须首先通过setAccessible(true)设置允许访问。
获取继承关系
获取父类的Class
有了Class实例,我们还可以获取它的父类的Class:
1 | public class Main { |
运行上述代码可以看到,Integer的父类类型是Number,Number的父类是Object,Object的父类是null,因为所有的类都是继承于 Objcet。
除Object外,其他任何非interface的Class都必定存在一个父类类型。
获取interface
通过clz.getInterfaces() 方法可以查询到该类实现的接口类型。
例如,查询Integer实现的接口:
1 | import java.lang.reflect.Method; |
运行上述代码可知,Integer实现的接口有:
- java.lang.Comparable
- java.lang.constant.Constable
- java.lang.constant.ConstantDesc
注意:
getInterfaces()只返回当前类直接实现的接口类型,并不包括其父类实现的接口类型- 如果一个类没有实现任何
interface,那么getInterfaces()返回空数组。
继承关系判断
要判断一个类是否可以赋值给另一个类(向上转型)可以调用isAssignableFrom()
1 | // Number n = ? |
动态代理
Java 中,是不能直接实例化 interface 的。
所有interface类型的变量总是通过某个实例向上转型并赋值给接口类型变量的:
1 | CharSequence cs = new StringBuilder(); |
但是 Java 标准库提供了一种动态代理(Dynamic Proxy)的机制:可以在运行期动态创建某个interface的实例。
就是不去实现,而是在代码运行中动态创建并使用。
通过JDK提供的一个Proxy.newProxyInstance()创建一个Hello接口对象。
1 | public class Main { |
动态创建 interface 实现类步骤
- 定义一个
InvocationHandler实例,它负责实现接口的方法调用; - 通过 Proxy.newProxyInstance() 创建 interface 实例,传入3个参数:
- 使用的
ClassLoader,通常就是接口类的ClassLoader; - 需要实现的接口数组,至少需要传入一个接口进去(这里传入接口本身的 Class 实例);
- 用来处理接口方法调用的
InvocationHandler实例。
- 使用的
- 将返回的
Object强制转型为接口。
注解
介绍
注解是放在Java源码的类、方法、字段、参数前的一种特殊“注释”。
区别于注释:
注释会被编译器直接忽略,注解则可以被编译器打包进入class文件,可以把注解看做是一种用作标注的“元数据”。
分类
Java的注解可以分为三类:
第一类是由编译器使用的注解,作用于编译阶段,例如:
@Override:让编译器检查该方法是否正确地实现了覆写;@SuppressWarnings:告诉编译器忽略此处代码产生的警告。
这类注解不会被编译进入.class文件,它们在编译后就被编译器扔掉了。
第二类是由底层工具处理.class文件使用的注解。
比如在加载class的时候对class做动态修改,实现一些特殊的功能(如Lombok加一些属性等)。
这类注解会被编译进入.class文件,但加载结束后并不会存在于内存中。
第三类是在程序运行期能够读取的注解,它们在加载后一直存在于JVM中,程序在运行中可以随时捕捉和处理。
例如,一个配置了@PostConstruct的方法会在调用构造方法后自动被调用(这是Java代码读取该注解实现的功能,JVM并不会识别该注解)。
定义注解
配置参数
定义一个注解时可以定义配置参数。配置参数必须是不可变类型,包括:
- 所有基本类型;
- String;
- 枚举类型;
- 基本类型、String、Class以及枚举的数组。
还允许为配置参数指定默认值,缺少某个配置参数时将使用默认值。
大部分注解会有一个名为value的配置参数,对此参数赋值,可以只写常量省略value参数名称。
即配置注解时,如果配置的参数名称是value,且只有一个参数,那么可以省略参数名称。
1 | public class Hello { |
定义格式
Java语言使用@interface语法来定义注解(Annotation),它的格式如下:
1 | public Report { |
元注解
有一些注解可以修饰其他注解,这些注解就称为元注解(meta annotation)。
Java标准库已经定义了一些元注解,我们只需要使用元注解,通常不需要自己去编写元注解。
@Target
最常用的元注解是@Target。使用@Target可以定义Annotation能够被应用于源码的哪些位置:
- 类或接口:
ElementType.TYPE; - 字段:
ElementType.FIELD; - 方法:
ElementType.METHOD; - 构造方法:
ElementType.CONSTRUCTOR; - 方法参数:
ElementType.PARAMETER。
例如,定义注解@Report可用在方法上,我们必须添加一个@Target(ElementType.METHOD):
1 |
|
定义注解@Report可用在方法或字段上,可以把@Target注解参数变为数组{ ElementType.METHOD, ElementType.FIELD }:
1 |
|
实际上@Target定义的value是ElementType[]数组,只有一个元素时,可以省略数组的写法。
@Retention
另一个重要的元注解@Retention定义了Annotation的生命周期:
仅编译期:
RetentionPolicy.SOURCE;提供给编译器使用,编译结束后会丢掉。
仅class文件:
RetentionPolicy.CLASS;用于修改底层class结构,不会被JVM加载。
运行期:
RetentionPolicy.RUNTIME。可以在程序运行中捕获和处理,最常用。
如果@Retention不存在,则该Annotation默认为CLASS。
因为通常我们自定义的Annotation都是RUNTIME,所以要加上@Retention(RetentionPolicy.RUNTIME)
1 |
|
@Repeatable
使用@Repeatable(Class)这个元注解可以定义Annotation是否可重复标注在同一个地方。
并将重复的注解读到目标 Class 的参数中。
1 | // 将多个 Report 记录到 Reports 注解中。 |
经过@Repeatable修饰后,在某个类型声明处,就可以添加多个@Report注解:
1 |
|
@Inherited
使用@Inherited定义子类是否可继承父类定义的Annotation。
@Inherited仅针对@Target(ElementType.TYPE)类型的annotation有效,并且对interface的继承无效:
1 |
|
在使用的时候,如果一个类用到了@Report:
1 |
|
则它的子类默认也定义了该注解:
1 | public class Student extends Person { |
自定义 Annotation 步骤
- 用
@interface定义注解:
1 | public Report { |
- 定义配置参数、默认值:
1 | public Report { |
把最常用的参数定义为value(),推荐所有参数都尽量设置默认值。
- 用元注解配置注解:
1 |
|
其中,必须设置@Target和@Retention,@Retention一般设置为RUNTIME,因为我们自定义的注解通常要求在运行期读取。一般情况下,不必写@Inherited和@Repeatable。
读取处理注解
SOURCE类型的注解主要由编译器使用,因此我们一般只使用,不编写。
CLASS类型的注解主要由底层工具库使用,涉及到class的加载,一般我们很少用到。
只有RUNTIME类型的注解不但要使用,还经常需要编写。
因此,以下方式针对 RUNTIME 类型处理。
读取注解:
判断某个注解是否存在于Class、Field、Method或Constructor:
Class.isAnnotationPresent(Class)Field.isAnnotationPresent(Class)Method.isAnnotationPresent(Class)Constructor.isAnnotationPresent(Class)
使用反射API读取Annotation:
Class.getAnnotation(Class)Field.getAnnotation(Class)Method.getAnnotation(Class)Constructor.getAnnotation(Class)
使用反射API读取Annotation有两种方法。
- 先判断
Annotation是否存在,如果存在,就直接读取:
1 | Class cls = Person.class; |
- 是直接读取
Annotation,如果Annotation不存在,将返回null:
1 | Class cls = Person.class; |
读取方法、字段和构造方法的Annotation和Class类似。
但要读取方法参数的Annotation就比较麻烦一点,因为方法参数本身可以看成一个数组,而每个参数又可以定义多个注解。
所以,方法参数的所有注解用一个二维数组来表示。
例如,对于以下方法定义的注解:
1 | public void hello( String name, String prefix) { |
要读取方法参数的注解,我们先用反射获取Method实例,然后读取方法参数的所有注解:
1 | // 获取Method实例: |
处理注解
注解本身只是一个标注,被标注的对象如何处理完全由程序自己决定。
例如,JUnit是一个测试框架,它会自动运行所有标记为@Test的方法。
以@Range注解标注一个String字段为例,要求标注了这个注解的字段长度满足注解配置参数要求:
- 定义注解
1 |
|
- 使用注解
1 | public class Person { |
- 处理注解
1 | void check(Person person) throws IllegalArgumentException, ReflectiveOperationException { |
这样一来,通过标注@Range注解,配合check()方法处理,就完成了Person实例的检查。
泛型
为什么需要泛型?
复用,类型安全,避免出现误转型
泛型的原理
“类型擦除”,自动转型。
定义泛型
1 | public class ArrayList<T> { |
在类名后头用<T>声明类型参数,这个类型可以是任意类型。
定义接口泛型也是类似
向上转型
ArrayList<Integer>不可以向上转型为ArrayList<Number>或List<Number>。
==泛型不一致不能向上转型==
如果允许成功赋值,在对它进行读取时就会出现类型错误,如 Double 写入了本就是 Integer 的 Number。
1 | // 创建ArrayList<Integer>类型: |
允许类型ArrayList<T>可以向上转型为List<T>,必须保证泛型一致。
T 可以是 ?,表示可以是任意类型
ArrayList<T>可以向上转型为 ArrayList<?>
泛型方法
1 | public class Pair<T> { |
像这种直接在静态方法中使用泛型参数会报错,但是可以用声明泛型方法的方式来使用泛型
1 | // 静态泛型方法应该使用其他类型区分: |
静态方法的泛型参数是区别于泛型类的,因为不用指定泛型也可以使用静态方法。
多个泛型
1 | public class Pair<T, K> { |
类似 Map<K, V>
使用泛型
使用ArrayList带有泛型的类时,如果不声明泛型类型时,泛型类型实际上就是Object:
1 | // 编译器警告: |
此时,只能把<T>当作Object使用,没有发挥泛型的优势,依旧需要手动转型。
当我们定义泛型类型<String>后,List<T>的泛型接口变为强类型List<String>:
1 | // 无编译器警告: |
如果类型声明了泛型类型,在 new 实例时可以省略,由编译器自动推断。
1 | // 可以省略后面的Number,编译器可以自动推断泛型类型: |
擦拭法
擦拭法是指,虚拟机对泛型其实一无所知,所有的工作像对泛型的检查和转换都是编译器做的。
擦拭法的效果:
- 编译器把类型
<T>视为Object; - 编译器根据
<T>实现安全的强制转型。
使用泛型的时候,我们编写的代码也是编译器看到的代码:
1 | Pair<String> p = new Pair<>("Hello", "world"); |
而虚拟机执行的代码并没有泛型:
1 | Pair p = new Pair("Hello", "world"); |
所以,Java的泛型是由编译器在编译时实行的,编译器内部永远把所有类型T视为Object处理,但是,在需要转型的时候,编译器会根据T的类型自动为我们实行安全地强制转型。
带来的局限
<T>不能是基本类型,因为基本类型无法对Object进行强制转型。- 泛型类的 Class 实例都是同一个
1 | Pair<String> p1 = new Pair<>("Hello", "world"); |
- 无法用 instanceof 判断带泛型的类型
1 | Pair<Integer> p = new Pair<>(123, 456); |
- 不能使用 new 关键字实例化 T 类型,因为实际上会变成
new Object()
不能覆写Object类的方法
1 | public class Pair<T> { |
如果覆盖了Object方法,会导致两个类被向上转型为Object时,出现类型转换错误。
泛型继承
一个类可以继承自一个泛型类。例如:父类的类型是Pair<Integer>,子类的类型是IntPair,可以这么继承:
1 | public class IntPair extends Pair<Integer> { |
使用的时候,因为子类IntPair并没有泛型类型,所以,正常使用即可:
1 | IntPair ip = new IntPair(1, 2); |
前面讲了,我们无法获取Pair<T>的T类型,即给定一个变量Pair<Integer> p,无法从p中获取到Integer类型。
但是在父类是泛型类型的情况下,编译器会把类型T(对IntPair来说,也就是Integer类型)保存到子类的class文件中,不然编译器就不知道IntPair只能存取Integer这种类型。
获取父类泛型类型
在继承了泛型类型的情况下,子类可以获取父类的泛型类型。
例如:IntPair可以获取到父类的泛型类型Integer。获取父类的泛型类型代码比较复杂:
1 | import java.lang.reflect.ParameterizedType; |
类型标识继承关系
extends、super
extends
1 | public class Main { |
? extends Number 表示该泛型可以是Number或其子类。
允许传入 Pair<Integer>。
这种使用<? extends Number>的泛型定义称之为上界通配符(Upper Bounds Wildcards),即把泛型类型T的上界限定在Number了。
如果声明的类型是 Pair<Number> ,无法传入 Pair<Integer> ,因为后者无法向上转型为前者。
限制:
方法参数签名setFirst(? extends Number)无法传递任何Number的子类型给setFirst(? extends Number)。
因为 Double 和 Integer 都可以传入,编译器会阻止这种类型不安全的行为。
例外:可以传入 null
1 | p.setFirst(null); // ok, 但是后面会抛出NullPointerException |
应用场景
使用 extends 限定 T 的上界
例如定义 Pair<T extends Number>,则该泛型参数 T 只能传入 Number 的子类。
T 和 ? 的区别:
? 表示一个通配符,可以传入任何类型。
T 表示一个泛型参数,在定义泛型类或方法时,需要用 T 来描述其他内容。
super
和 extends 相反,super 限定了 T 的下界。
1 | void set(Pair<? super Integer> p, Integer first, Integer last) { |
? super Integer 表示接收泛型类型为 Integer 或其父类。
限制
super 允许写,不允许读。
因为类型无法向下转型。
对比extends和super通配符
我们再回顾一下extends通配符。作为方法参数,<? extends T>类型和<? super T>类型的区别在于:
<? extends T>允许调用读方法T get()获取T的引用,但不允许调用写方法set(T)传入T的引用(传入null除外);<? super T>允许调用写方法set(T)传入T的引用,但不允许调用读方法T get()获取T的引用(获取Object除外)。
一个是允许读不允许写,另一个是允许写不允许读。
先记住上面的结论,我们来看Java标准库的Collections类定义的copy()方法:
1 | public class Collections { |
为什么 super 支持写,extends 支持读
写:因为 super 可以传入 T 的超类,此时的泛型就有可能是 T 或其超类,在 set 时就允许向上转型赋值;而 extends 允许传入子类,如果对其赋值,就是向下转型了。
写:因为 extends 允许传入子类,此时的泛型就是 T 或其子类,那么 get 时,就可以使用 T (上界)来接收,满足向上转型,而 super 允许传入超类,此时这个 T 就是它的下界,不允许向下赋值。
因此,super和extends的读写,可以单独允许Object和null
无限定通配符
Java的泛型还允许使用无限定通配符(Unbounded Wildcard Type),即只定义一个?:
因为<?>通配符既没有extends,也没有super,因此:
- 不允许调用
set(T)方法并传入引用(null除外); - 不允许调用
T get()方法并获取T引用(只能获取Object引用)。
换句话说,既不能读,也不能写,那只能做一些null判断:
1 | static boolean isNull(Pair<?> p) { |
大多数情况下,可以引入泛型参数<T>消除<?>通配符:
1 | static <T> boolean isNull(Pair<T> p) { |
<?>通配符有一个独特的特点,就是:Pair<?>是所有Pair<T>的超类:
泛型和反射
泛型 Class
Java的部分反射API也是泛型。例如:Class<T>就是泛型:
1 | // compile warning: |
调用Class的getSuperclass()方法返回的Class类型是Class<? super T>:
1 | Class<? super String> sup = String.class.getSuperclass(); |
泛型 Constructor
构造方法Constructor<T>也是泛型:
1 | Class<Integer> clazz = Integer.class; |
泛型数组
我们可以声明带泛型的数组,但不能用new操作符创建带泛型的数组:
1 | Pair<String>[] ps = null; // ok |
可以通过强制转型实现“带泛型”的数组:
1 |
|
但是数组实际上在运行期没有泛型,而是 Pair<Object>[]。
因为类型擦拭,只能通过编译器来强制检查变量ps。
注意:通过绕过泛型声明的引用依旧可以使用任意类型修改创建的数组
1 | Pair[] arr = new Pair[2]; |
虽然这两个变量实际上指向同一个数组,但是操作arr可以传入非String的参数。
要安全地使用泛型声明数组,必须扔掉原来arr的引用:
1 |
|
上面的代码中,由于拿不到原始数组的引用,就只能对泛型数组ps进行操作,这种操作就是安全的。
带泛型的数组实际上是编译器的类型擦除:
1 | Pair[] arr = new Pair[2]; |
所以我们不能直接创建泛型数组T[],因为擦拭后代码变为Object[]:
1 | // compile error: |
创建泛型数组
- 借助
Class<T>来创建泛型数组:
1 | T[] createArray(Class<T> cls) { |
- 利用可变参数创建泛型数组
T[]:
1 | public class ArrayHelper { |
谨慎使用泛型可变参数
在上面的例子中,我们看到,通过:
1 | static <T> T[] asArray(T... objs) { |
似乎可以安全地创建一个泛型数组。但实际上,这种方法非常危险。
1 | import java.util.Arrays; |
直接调用asArray(T...)没有问题,直接将获取到的类型参数数组返回。
而如果在另一个方法中调用该方法,传入参数时,参数的类型已经被擦除了。
所以就会返回Object[],然后产生ClassCastException。
编译器对所有可变泛型参数都会发出警告,只有确认完全没有问题,才可以用@SafeVarargs消除警告。
==如果在方法内部创建了泛型数组,最好不要将它返回给外部使用。==
集合
List
使用
List 只是一个接口,用来规范使用方法。
- 在末尾添加一个元素:
boolean add(E e) - 在指定索引添加一个元素:
boolean add(int index, E e) - 删除指定索引的元素:
E remove(int index) - 删除某个元素:
boolean remove(Object e) - 获取指定索引的元素:
E get(int index) - 获取链表大小(包含元素的个数):
int size()
要创建一个 List 实例,可以借助 ArrayList 或 LinkedList。
一个是线性表,一个是链表,区别如下。
| ArrayList | LinkedList | |
|---|---|---|
| 获取指定元素 | 速度很快 | 需要从头开始查找元素 |
| 添加元素到末尾 | 速度很快 | 速度很快 |
| 在指定位置添加/删除 | 需要移动元素 | 不需要移动元素 |
| 内存占用 | 少 | 较大 |
List.of
Java 11以后,可以用 List.of(…T) 静态方法创建一个只读的列表。
注意:
- 不允许传入 null
- 对只读
List调用add()、remove()方法会抛出UnsupportedOperationException。
List转Array
直接调用 toArray 方法,返回 Object 类型数组。
1
Object[] array = list.toArray();
传入一个数组,返回该数组。
1
Integer[] arr = list.toArray(new Integer[5]);
注意:
- 传入的数组类型如果和list类型无法兼容,会抛出
ArrayStoreException - 如果传入的数组容量比list小,会被截掉
- 传入的数组类型如果和list类型无法兼容,会抛出
传入数组的构造方法引用
1 | Integer[] arr = intList.toArray(Integer[]::new) |
Array转List
1 | List<Integer> list = Arrays.asList(...T) |
Map
使用
同 List,Map 只是一个接口
常用方法
- 插入元素:
V put(K key, V value) - 访问value:
V get(K key) - 是否包含某个key:
boolean containsKey(K key) - 是否包含某个value:
boolean containsValue(K key) - 返回所有的key:
Set<K> keySet() - 返回所有的value:
Collection<V> values() - 返回所有的键值对:
Set<Entry<K, v>> entrySet()
注意:
- 不存在重复的key,如果对相同的key进行put,会替换掉这个key映射的value,并返回上次的value。
- keySet 不一定是有序的。
实现类
- HashMap:无序
- TreeMap:有序,可以传入一个比较器来给key排序,默认按照key本身的Comparator
HashMap的本质
通过空间换时间,用一个大数组来存储value,这样就可以直接索引。
步骤:
- 再通过 key 的 hashCode 方法计算出 hash 值,即该 key 对应 value 在数组中存储的索引值。
- 如果 hash 值相同,再根据 key 的 equals 方法重新计算。
数组长度
HashMap 初始化时默认的数组大小只有 16。
通过类似如下算法的方式,控制 hash 值的分布范围:
1 | int index = key.hashCode() & 0xf; // 0xf = 15 |
如果添加到超过初始长度后,内部会进行扩容。
==为了能方便进行位运算,每次扩容后的长度会保证为 2^n^==
为了保证性能,最少创建时就指定相应的容量
使用 ArrayList 实现类同理
1 | Map<String, Integer> map = new HashMap<>(10000); |
虽然指定容量是10000,但HashMap内部的数组长度总是2n,因此,实际数组长度被初始化为比10000大的16384(214)。
hashcode重复
假如存入了两个 key,但是非常巧合的是它们的 hashcode 重复了。
那么,在HashMap的数组中,存储的就不是一个 value 了
而是一个由重复的 hashcode 对应 key 的 value 的 List,包含这两个 key 对应的键值对。
于是查找的方法,就不只是直接索引了,而是索引之后再遍历这个 list,找到相应的 key。
如果冲突的概率越大,这个List就越长,Map的get()方法效率就越低
不同的key具有相同的hashCode()的情况称之为哈希冲突。
在冲突的时候,一种最简单的解决办法是用
List存储hashCode()相同的key-value。也可以用链表,树等结构
总之:hash 值的唯一性决定了 HashMap 的查询性能。
对比 Hashtable
- 继承类不同 dictionary
- 提供接口不同
- 对 key-value 的 null 值
- 线程安全
- 遍历方式
- 容量分配
- hash值计算方式
Set
使用
Set用于存储不重复的元素集合,它主要提供以下几个方法:
- 将元素添加进
Set<E>:boolean add(E e) - 将元素从
Set<E>删除:boolean remove(Object e) - 判断是否包含元素:
boolean contains(Object e)
HashSet的本质
HashSet仅仅是对HashMap的一个简单封装,只管理key,而放入相同的Object作为value。
1 | public class HashSet<E> implements Set<E> { |
SortedSet
Set 是无序的,而 SortedSet 接口继承至 Set,并且是有序的。
实现类是:TreeSet,需要传入一个比较器,如果没有就使用 key 默认的比较器。
IO
File类,与输入输出流都存放在Java.io包内。
==所有的输入输出类,都必须被异常处理包裹,捕捉FileNotFoundException==
1. File类
File对象主要用来获取文件本身的一些信息,不涉及对文件的读写操作。
构造函数
- File(String filename);
- File(String directoryPath,String filename);
- File(File f,String filename);
==即使文件不存在,也不会报出异常==
常用方法
- public String getName() 获取文件的名字。
- public boolean canRead() 判断文件是否是可读的。
- public boolean canWrite() 判断文件是否可被写入。
- public boolean exits() 判断文件是否存在。
- public long length() 获取文件的长度(单位是字节)。
即长度为该文件内容为多少个字节,返回类型是long。
假如文件内容为:我是who12(整型)1000(long类型),那么读取到的length为4+3+4+8 = 19个字节。
- public String getAbsolutePath() 获取文件的绝对路径。
- public boolean isFile() 判断文件是否是一个普通文件,而不是目录。
- public boolean isDirectroy() 判断文件是否是一个目录。
2. 输入输出流
- FileInputStream
以字节的形式读取文件
FileInputStream(String name);
FileInputStream(File file);
int read() 读取单个字节的数据
int read(byte b[]) 读取到字节数组b中,返回读取的实际字节长度,如果到达文件末尾则返回-1。
int read(byte b[],int off,int len) 读取文件内容从off位置len个字节到字节数组b中
- FileOutputStream
以字节的形式写入文件
区别 void write(byte b[],int off,int len) 从字节数组中偏移量off处取len个字节写到目的地。
- FileReader
以字符的形式读取文件
nt read() 读取单个字符的数据
int read(char b[]) 读取到字符数组b中
int read(char b[],int off,int len) 读取从off位置len个字符到字符数组b中
- FileWriter
以字符的形式写入文件
使用方法类比即可
3. 缓冲流
缓冲流只能指向FileWriter或FileReader类对象,相较于提供了更多输入输出的方法,可以提高大文件(数据)的读写速度。
- BufferedReader,BufferedWriter
readLine() 读取文本行
write(String s,int off,int len) 把字符串s写到文件中
newLine(); 向文件写入一个回行符
4. 随机访问文件流
RandomAccessFile类可以同时实现输入和输出操作。
构造函数:
RandomAccessFile(String name,String mode) ;
RandomAccessFile(File file,String mode) ;
mode指对文件的操作方式,如:r 表示只读,rw表示读和写,w表示写入。
使用方法:
read();
writeInt(); writeLong();
seek(long a) 定位RandomAccessFile流的读写位置
getFilePointer() 获取流的当前读写位置
还有对象流(用来输入输出对象)等一些乱七八糟的
日期与时间
正则表达式
加密与安全
多线程
多线程可以让程序同时执行多个任务。
但它的本质是多个任务轮流进行,比如让浏览器执行0.001秒,让QQ执行0.001秒,再让音乐播放器执行0.001秒,在人看来,CPU就是在同时执行多个任务。
即使是多核CPU,因为任务的数量往往多于CPU的核数,所以任务也是交替进行的。
为什么多线程操作在程序中往往比单线程快?
以MySQL插入数据为例
因为MySQL内部将调度任务分为了多个线程,如果插入操作是单线程的,就无法占满所有的线程。
相当于给你10个工人,你却只用了一个工人。
为什么MySQL内部需要多线程?
可能是因为有一些操作需要同时进行,如守护线程 :question:
总之:在应用多线程中间件(到达目的地的管道)时,同时使用多线程操作才会比单线程快。
进程与线程
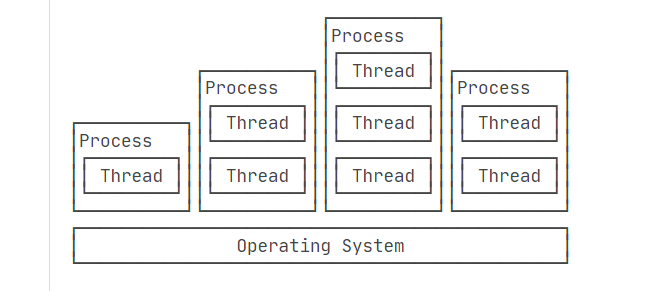
在计算机中,一个任务整体称为一个进程。
例如,浏览器就是一个进程,视频播放器是另一个进程,类似的,音乐播放器和Word都是进程。
一个任务整体(进程)里可以包含多个子任务(线程)。
例如,浏览器可以打开多个窗口,同时查看不同网站的内容,此时浏览器进程程执行了多个显示窗口的线程。
进程与线程的关系:一个进程可以包含一个或多个线程,但至少会有一个线程。
操作系统调度的最小任务单位其实不是进程,而是线程。
多进程和多线程对比:
多进程的缺点:
开销大,创建进程开销大,尤其是在Windows系统上;
通信慢,进程间通信 比 线程间通信要慢,因为线程间通信就是读写同一个变量,速度很快。
多进程的优点:
稳定性高,多进程稳定性比多线程高,
因为在多进程的情况下,一个Java进程崩溃不会影响其他进程,而在多线程的情况下,任何一个线程崩溃会直接导致整个进程崩溃。
JVM 多线程
Java 语言内置了多线程支持,一个Java程序实际上是一个JVM进程。
JVM进程用一个主线程来执行main()方法,在main()方法内部也可以启动多个子线程。
此外,JVM还有负责垃圾回收的其他工作线程等。
和单线程相比,多线程编程的特点在于:多线程经常需要读写共享数据,并且需要同步。
创建线程
创建步骤:
- 实例化一个Thread类对象,重写 run() 方法。
- 再调用Thread对象的start()方法,开启一个新线程。
- 线程启动后,会自动调用Thread对象的 run() 方法。
在这种创建方法中,run方法体的内容就代表这该线程需要执行的任务。
重写 run 的几种方法:
- 继承
Thread类,重写run()方法:
1 | class MyThread extends Thread { |
- 创建
Thread实例时,传入一个Runnable实例:
1 | public class Main { |
- 或者直接传入Runable接口匿名类
1 | public class Test { |
- 也可以使用 Java 8 后的 lambda 表达式
1 | public class Test { |
- 又或者创建 Thread 匿名类,重写run方法
1 | public class Test { |
注意:
在通过start()方法启动新线程后,该线程不一定立即执行。
直接调用线程的run()方法,无法启动新线程,只是执行一个普通方法而已。
线程的开启由 start() 方法代理,执行 run() 方法内容。
线程休眠
通过调用 Thread.sleep(milliseconds) 静态方法,可以使线程休眠 x 毫秒
线程休眠方法会抛出 InterruptedException checked异常,必须显式捕获异常。
1 | try { |
设置线程的优先级
可以在线程内部调用 Thread.setPriority(n)设置线程的优先级(1 - 10),默认值是5。
优先级高的线程被操作系统调度的优先级较高。
操作系统对高优先级线程可能调度更频繁,但无法确保高优先级的线程一定会先执行。
线程的状态
一个新的线程开启后,只会执行一次 run 方法,执行完毕代表该线程结束。
线程的状态有以下几种:
- New:新创建的线程,尚未执行;
- Runnable:运行中的线程,正在执行
run()方法的Java代码; - Blocked:运行中的线程,因为某些操作被阻塞而挂起;
- Waiting:运行中的线程,因为某些操作在等待中;
- Timed Waiting:运行中的线程,因为执行
sleep()方法正在计时等待; - Terminated:线程已终止,因为
run()方法执行完毕。
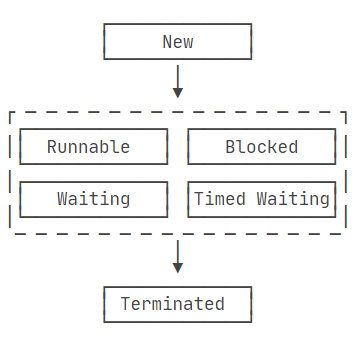
当线程启动后,它可以在Runnable、Blocked、Waiting和Timed Waiting这几个状态之间切换,直到最后变成Terminated状态,线程终止。
线程终止的原因有:
- 线程正常终止:
run()方法执行到return语句返回; - 线程意外终止:
run()方法因为未捕获的异常导致线程终止; - 对某个线程的
Thread实例调用stop()方法强制终止(强烈不推荐使用)。
等待线程
一个线程还可以等待另一个线程直到其运行结束。
例如,main线程在启动t线程后,可以通过t.join()等待t线程结束后再继续运行。
1 | public class Main { |
join 含义理解:
t 线程加入 main 线程任务中,作为任务执行的一个步骤,只有等 t 执行完毕,main 线程任务的步骤才可以继续往下执行。
==改正:不是等 t 执行完毕,而是等该线程调度结束,例如,死循环线程不会一直执行。==
如果t线程已经结束,对实例t调用join()会立刻返回。
此外,join(long)的重载方法也可以指定一个等待时间,超过等待时间后就不再继续等待(就不要它加入了嘿嘿)。
中断线程
如果线程需要执行一个 长时间任务,就可能需要能控制的中断线程,确保这个任务是可控的。
中断线程有三种方法:
- 调用线程对象的
interrupt()方法
通过调用interrupt方法,给线程传递一个中断的信号。
目标线程需要通过调用继承 Thread 的 isInterrupted() 方法,反复检测自身状态是否是 interrupted 状态。
1 | public class Main { |
解释:首先开启了一个新的线程 t,该线程监听中断信号不断循环输出 hello(模拟长时间任务),然后 main 线程发出中断信号,同时 t 线程中的循环监听到了中断信号,随后停止运行,重新回到 main 线程继续执行,最后输出 “end”。
注意:如果线程内没有检测中断信号,只是调用 interrupt() 方法线程是不会中断的。
应用场景:
首先需要注意的是,通过 interrupt 方法中断线程的前提,是目标线程必须时刻监听中断信号。
因此,目标线程应该将长时间任务转化为分片的任务,循环进行,同时监听中断信号。
- 监听目标线程内其他线程的 join 方法。
假设有两个线程 A,B。
A 线程中对 B 线程调用了 join() 方法,而此时 A 线程又收到了 interrupt 信号
那么 join 方法就会抛出一个 InterruptedException 异常,A 线程就会结束运行。
结束点:目标线程内部其他线程的 join 时刻
1 | public class Test { |
为什么线程 B 监听了中断信号,在捕获异常时还需要 break?
因为在对 B 线程调用 interrupt 方法时,如果线程 B 本身就在 waiting,sleeping 状态时,内部的 sleep 方法会抛出 InterrputedException 异常,并重置中断状态(isInterrupted=false),所以要在捕获到异常时break。
:question: 上方答案存疑
- 定义标志变量结束线程
例如,定义一个变量 running,然后在目标线程中监听其值来决定是否结束线程(类似 Thread 自身维护的 isInterrupt)。
1 | public class Main { |
running 在此处代码中,同时作为了 main 和 t 线程之间共享的变量。
变量的更新机制
在Java虚拟机中,变量是保存在主内存的。
每个线程访问变量时,会先生成一个副本保存在自己的工作内存中。
如果线程修改了变量的值,虚拟机会在不确定的时刻再把修改后的值写回到主内存,存在线程之间变量不一致的问题!
例如,running = false,然后 main 修改其为 true,但是没有写到主内存,那么此时线程 A 访问 running 仍会的到 true,而不会立刻结束线程,只有在回写到主内存后才会结束线程。
而 volatile 关键字的目的是告诉虚拟机:
- 每次访问变量时,总是获取主内存的最新值;
- 每次修改变量后,立刻回写到主内存。
这样就可以确保线程之间变量的一致性。
守护线程
有一种线程的目的就是无限循环,无法设定结束条件。
例如,一个定时任务的线程。
1 | class TimerThread extends Thread { |
已知 JVM 需要所有线程都运行结束后,才会退出。
如果存在这样一个无限执行的线程,且与任务无关,但是又需要在所有任务结束后,关闭 JVM 终止程序,该如何操作呢。
答案:守护线程。
守护线程是指为其他线程服务的线程。
JVM 关闭时无需关心守护线程是否结束,只要其他线程结束就终止程序,同时顺带关闭守护线程。
创建守护线程:
1 | Thread t = new MyThread(); |
目标线程通过调用 setDeamon(true);来将本线程设为守护线程。
注意:守护线程不应该持有任何需要手动关闭的资源,如打开文件。因为该线程何时关闭是不确定的,无法释放资源。
线程同步
同步:指两个变量始终保持一定的相对关系,可以是同时,也可以是完成同一个操作一前一后(你先做,再到我做)。
从 volatile 那一节中知道,如果多个线程同时读写共享的变量,会出现数据不一致的问题。
假设有两个加法线程,同时操作同一个变量,都执行加法操作。
1 | n = n + 1; |
这一行语句被 JVM 解析成 3 条指令
1 | ILOAD |
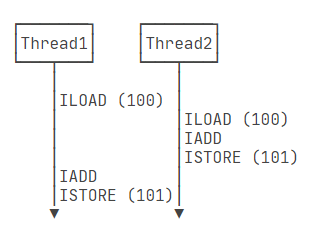
如果线程 1 在LOAD后就被中断,转而执行线程 2,此时 n 还是 100,就会出现两个线程同时写入 101 给 n,而不是正常的 102。
如何让线程 2 每次都基于线程 1 的结果继续运算呢?
只需要保证当一个线程进行 LOAD, ADD, STORE 操作时,其他线程必须等待这一个线程执行完之后再依次执行,确保操作的原子性。
这样的操作被称为原子操作
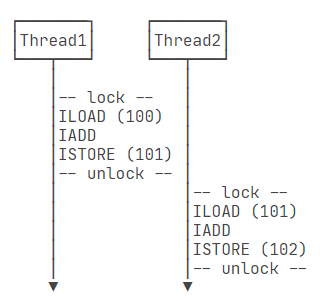
这样的操作称为加锁,解锁。
通过加锁和解锁的操作,就能保证3条指令执行期间只有一个线程,不会有其他线程会进入此指令区间。
只有在执行线程解锁,将锁释放后,其他线程才能获得锁并执行这 3 条指令。
synchronized
Java 使用 synchronized 关键字对一个对象进行加锁,保证了代码块在任意时刻最多只有一个线程能执行。
1 | public class Main { |
这里以 lock 作为锁,每个线程执行加减操作时需要先获取锁,如果这把锁被其他线程占用了,就需要等待锁被释放后,重新获取锁才能执行。
保持线程之间同步的步骤:
- 划出需要同步的代码块;
- 选择同一个对象作为锁;
- 使用
synchronized(lockObject) { ... }包裹代码块。
注意:
- 锁的对象必须是同一个,如果不同就会有两把锁,出现两个线程异步执行的情况。
- 获取锁和释放锁需要消耗一定的时间,所以,
synchronized会降低程序的执行效率、性能。 - 不用担心同步过程中会抛出异常,锁会被正确释放。
原子操作
具有原子性的操作被称为原子操作。原子:不可以再被分解的物质。
原子操作是指不能被中断的一个或一系列操作。
对于原子操作不需要使用锁,因为每一个原子操作,都是在“一下”完成的,不被其他线程打断。
JVM规范定义了几种原子操作:
- 基本类型(
long和double除外,没有明确规定)赋值,例如:int n = m; - 引用类型赋值,例如:
List<String> list = anotherList。
但如果是多行赋值操作,就需要给操作加锁(对象本身)了。
锁的对象随实际需要改变,这里假设多个线程用到了同一个 Pair 实例对象。
1 | class Pair { |
如果“写”操作不加锁,就会出现当 A 线程给 pair 对象的 x 赋值时,被 B 线程打断并重新把 x 赋值为另一个值,这时候 A 线程的逻辑就会不严谨。
假设当前坐标是(100, 200)。
那么当设置新坐标为(110, 220)时,如果“读”操作不加锁,读到的值可能有:
- (100, 200):x,y更新前;
- (110, 200):x更新后,y更新前就调用了 pair 的 get 方法;
- (110, 220):x,y更新后。
加锁可以保证读的值不被污染,并且是最新。
有时也可以巧妙的将非原子操作转换为原子操作
1 | class Pair { |
这里的 ps 是局部变量,不被其他线程可见,不存在被其他线程中途修改的问题。
每个线程都会有各自的局部变量,互不影响,并且互不可见,并不需要同步。
将多行赋值改为引用赋值,确保操作被“一次”执行,保证原子性。
同理这里的读操作也转为了原子操作,x,y 每次都同步读取,不存在读了线程 A 设置的 x 后,y 又变成了线程 B 设置的。
缺点就是无法保证每次都是最新的状态,可以再添加 volatile 关键字,确保实时性。
看到这里应该就明白 volatile 和 synchronized 之间的区别的吧。
区别:
- volatile 只用于保证状态更新后能被实时写入主内存,保证状态的实时性。
- synchronized 则用于保证一连串操作同时只有一个线程在执行。
如果用 volatile 来限制 n = n + 1,只能确保每个线程更新后能立马写回主内存,但无法确保每个线程用来更新的值是其他线程执行完之后的值,还是操作了同一个值。
总之,volatile 只注重变量被赋值后“真正”更新的实时性。
不可变对象无需同步
如果多线程读写的是一个不可变对象(如String,List),那么无需同步。
因为不会修改这个对象的状态,而是修改对象本身。
1 | class Data { |
注意到set()方法内部创建了一个不可变List,这个List包含的对象也是不可变对象String,因此,整个List<String>对象都是不可变的,因此读写均无需同步。
对于读写的操作的同步问题
其实只需要多加思考如何保证写的操作是“阶段性”的,那么读就很容易保持阶段性(同步)。
总结多线程
深入理解多线程还需理解变量在栈上的存储方式,基本类型和引用类型的存储方式也不同。
什么时候需要考虑多线程问题?
- 并发高的场景
- 修改线程共享变量(对象变量等)的时候
为什么需要多线程?
每个任务分别做一点,和任务交替完成,总和不是一样的吗?
是的,但是前提是这写些个任务之间是可以“相加”的关系,前后结果没有太大联系。
但如果前一个任务和后一个任务中,有一部分成果是一致的呢?基于某一个相同的结果呢?
==那多线程带来的效率就是幂级的提升==
synchronized 方法
在业务逻辑中,如果自由的自定义 synchronized 代码块,会显得代码逻辑混乱。
因此,常常将同步的行为整体封装为一个类,如计数器。
1 | public class Counter { |
该计数器的加减操作以自身 this 实例为锁,支持同时创建多个实例,每个实例内部维护各自的 COUNT 不因为线程而错乱。
如果一个类被设计为允许 多线程 正确访问,我们就说这个类是线程安全的。
还有一些不变类,例如String,Integer,LocalDate,它们的所有成员变量都是final,多线程同时访问时只能读不能写,这些不变类也是线程安全的。
最后,类似Math这些只提供静态方法,没有成员变量的类,也是线程安全的。
事实上大部分情况下,大部分类,例如ArrayList,都是非线程安全的类,我们不能在多线程中安全的使用它们。
即使是上升为 List 引用,也是线程非安全的,因为内部的作用域还是 ArrayList 本身
只能访问,不能插入和修改元素,因为 length 和 元素内存值 会不一致。
==没有特殊说明时,一个类默认是非线程安全的。==
因为内置线程安全会影响性能,应交由开发者自由控制。
synchronized 方法修饰符
当锁的对象是 this 实例时,以下两种写法等价。
1 | public void add(int n) { |
static 方法加锁
由于 static 方法没有 this 实例,因此其锁住的是一个类的 Class 实例
1 | public class Counter { |
死锁
Java的线程锁是可重入的锁。
可重入锁
1 | public class Counter { |
上述代码先执行 add,然后在 add 内部再执行 dec,可以看到两个方法都是以 this 为锁对象的。
像这种同一把锁可以允许同一个线程多次获取的情况,就是可重入锁。
如果不同线程获取不同锁呢?
会造成 死锁 发生。
死锁通俗来说,就是这把锁无法被再次正常使用了,获取不到也释放不了。
1 | public void add(int m) { |
假设同时有两个线程,分别执行 add 和 dec 方法,首先都获取到了 lockA 和 lockB,就会出现这样一个情况:
- 线程1:准备获得
lockB,失败,等待中; - 线程2:准备获得
lockA,失败,等待中。
两个线程都因为想要获取对方的锁,而无限等待,造成死锁。
死锁发生后,没有任何机制能解除死锁,只能强制结束JVM进程。
==如何避免死锁==
答案:只要保证获取锁的顺序一致。
所有线程都遵循这个顺序同步,只要存在线程获取到锁开始了,其他线程就必须等待,不允许步骤交叉进行。
将 dec 方法改为如下代码,即可避免死锁。
1 | public void dec(int m) { |
当然,大部分情况下的业务逻辑都比这个复杂,可能这个服务和另一个服务交叉获取了锁,无法被明显的发现而造成死锁。
这时候可以借助第三方工具,如 redis,给“锁”设置一个过期时间,超出过期时间后就自动释放。
wait和notify
synchronized 解决了多线程竞争问题,但是没有解决协调问题。
竞争:多个线程争夺执行权
协调:多个线程之间配合交换执行权
1 | class TaskQueue { |
上述代码看上去没有问题:getTask()内部先判断队列是否为空,如果为空,就循环等待,直到另一个线程往队列中放入了一个任务,while()循环退出,就可以返回队列的元素了。
但实际上while()循环永远不会退出。因为线程在执行while()循环时,已经在getTask()入口获取了this锁,其他线程根本无法调用addTask(),因为addTask()执行条件也是获取this锁。
在队列为空的时候 getTask 获取了锁并进入了死循环,导致永远无法 addTask,造成了逻辑死锁。
正确的逻辑:一个线程可以调用getTask()从队列中获取任务。如果队列为空,则该线程应该等待,直到其他线程往队列中添加了任务之后被唤醒。
借助 wait 和 notify 改造代码
1 | class TaskQueue { |
当队列为空时,该线程调用 wait 方法等待。
wait 期间会释放线程获得的锁,wait()方法返回后,线程又会重新试图获得锁。
wait()方法必须在当前获取的锁对象上调用,这里获取的是this锁,因此调用this.wait()。
notifyAll 和 notify
内部调用了this.notifyAll()而不是this.notify(),使用notifyAll()将唤醒所有当前正在this锁等待的线程,而notify()只会唤醒其中一个(具体哪个依赖操作系统,有一定的随机性)。
通常来说,notifyAll()更安全。有些时候,如果我们的代码逻辑考虑不周,用notify()会导致只唤醒了一个线程,而其他线程可能永远等待下去醒不过来了。
注意:
在while()循环中调用wait(),而不是if语句:
1 | public synchronized String getTask() throws InterruptedException { |
上述的写法是错误的,因为可能会有多个线程同时 getTask,而没有获取到锁的线程,会再次进入 wait,如果这里是 if 的话,当线程被唤醒后不会继续判断,而是继续往下执行。
ReentrantLock
Java 5开始,引入了 java.util.concurrent 并发工具包。
它提供了大量更高级的并发功能,能大大简化多线程程序的编写。
虽然 Java 可以直接用synchronized关键字加锁,但这种锁有很大的缺点。
- 使用起来不方便,需要嵌套代码,非常“重量级”
- 获取锁失败时必须一直等待,没有额外的尝试,等待超时机制。
java.util.concurrent.locks 包提供的 ReentrantLock 可以用于替代 synchronized 加锁,也是一把可重入锁。
分别给出 synchronized 和 ReentrantLock 加锁代码:
synchronized
1 | public class Counter { |
ReentrantLock
1 | public class Counter { |
为确保锁住是 this 实例,将 ReentrantLock 声明为对象属性。
对比
因为synchronized是Java语言层面提供的语法,所以我们不需要考虑异常。
而ReentrantLock是Java代码实现的锁,我们就必须先手动获取锁,然后在确保无论是否发生异常,都要在finally中正确释放锁。
尝试机制
1 | // 尝试获取锁,最多等待 1 秒 |
通过 tryLock 尝试获取锁并设置尝试的时间,返回一个 boolean 值。
如果超时返回 false,可以进行一些额外的操作,而不是一直等待下去。
Condition
synchronized 具有 wait 和 notify 功能,ReentrantLock 该如何呢?
同样提供了 Condition 类,可以使用Condition对象来实现wait和notify的功能。
1 | class TaskQueue { |
使用方式和 wait 和 notify 类似。
注意:引用的Condition对象必须从Lock实例的newCondition()返回,这样才能正确协调获取这同一把锁的线程。
Condition提供的await()、signal()、signalAll()原理和synchronized锁对象的wait()、notify()、notifyAll()是一致的,并且其行为也是一样的:
await()会释放当前锁,进入等待状态;signal()会唤醒某个等待线程;signalAll()会唤醒所有等待线程;- 唤醒线程从
await()返回后需要重新获得锁。
此外,和tryLock()类似,await()可以在等待指定时间后,如果还没有被其他线程通过signal()或signalAll()唤醒,可以自己醒来:
1 | if (condition.await(1, TimeUnit.SECOND)) { |
ReadWriteLock
1 | public class Counter { |
ReentrantLock 保证了某一段操作同时只有一个线程在执行,但是对于不影响内存的操作:“读”,难道也只能同时允许一个线程进入吗??
但是如果不加锁,又会出现数据不一致的情况。
实际上我们想要的是:允许多个线程同时读,但只要有一个线程在写,其他线程就必须等待:
| 读 | 写 | |
|---|---|---|
| 读 | 允许 | 不允许 |
| 写 | 不允许 | 不允许 |
使用ReadWriteLock可以解决这个问题,它保证:
- 只允许一个线程写入(其他线程既不能写入也不能读取);
- 没有写入时,多个线程允许同时读(提高性能)。
1 | public class Counter { |
内部应该是维护了一个状态量,同时监控读写锁的状态,满足 无写-无读 的情况才可以写
使用ReadWriteLock时,适用条件是同一个数据,有大量线程读取,但仅有少数线程修改。
例如,一个论坛的帖子,回复可以看做写入操作,它是不频繁的,但是,浏览可以看做读取操作,是非常频繁的,这种情况就可以使用ReadWriteLock。
StampedLock
ReadWriteLock 仍然存在效率问题。
如果有线程正在读,写线程需要等待读线程释放锁后才能获取写锁,即读的过程中不允许写,这是一种悲观的读锁。
悲观:读的过程中一定会有其他线程执行写操作,为确保一致性应拒绝。
而 StampedLock 是一种乐观锁,允许在读的同时进行写;但是这样会造成数据不一致,需要额外编写代码维护一致性。
乐观:读的过程不会被写入,允许写操作。
1 | public class Point { |
给乐观读的操作加一个 validate 确保数据一致性,如果有其他线程写入,则获取悲观读锁重新读,保证一致性。
Semaphore
Semaphore:信号量。
前面学习各种锁的实现。
本质上锁的目的是保护一种受限资源,保证同一时刻只有一个线程能访问(ReentrantLock),或者只有一个线程能写入(ReadWriteLock)。
还有一种受限资源,目的是控制一种资源访问量,可能是不存在并发问题的只读操作。
例如,一个服务器同时只能允许 10 个人进入。
1 | public class AccessLimitControl { |
调用acquire()可能会进入等待,直到满足条件为止。也可以使用tryAcquire()指定等待时间:
1 | if (semaphore.tryAcquire(3, TimeUnit.SECONDS)) { |
如果要对某一受限资源进行限流访问,可以使用Semaphore,保证同一时间最多N个线程访问受限资源。
线程容量和QBS区别
Concurrent集合
在前面通过 ReentrantLock 和 Condition 实现了一个阻塞的任务队列 BlockingQueue。
BlockingQueue的意思就是说,当一个线程调用这个getTask()方法时,该方法内部可能会让线程变成等待状态,直到队列条件满足不为空,线程被唤醒后,getTask()方法才会返回。
除了BlockingQueue外,针对List、Map、Set、Deque等,java.util.concurrent包也提供了对应的并发集合类。我们归纳一下:
| interface | non-thread-safe | thread-safe |
|---|---|---|
| List | ArrayList | CopyOnWriteArrayList |
| Map | HashMap | ConcurrentHashMap |
| Set | HashSet / TreeSet | CopyOnWriteArraySet |
| Queue | ArrayDeque / LinkedList | ArrayBlockingQueue / LinkedBlockingQueue |
| Deque 双向队列 | ArrayDeque / LinkedList | LinkedBlockingDeque |
使用这些并发集合与使用非线程安全的集合类完全相同。我们以ConcurrentHashMap为例:
1 | Map<String, String> map = new ConcurrentHashMap<>(); |
操作和原生集合使用一致,所有的同步和加锁的逻辑都在集合内部实现了
java.util.Collections工具类还提供了一个旧的线程安全集合转换器,可以这么用:
1 | Map unsafeMap = new HashMap(); |
但是它实际上是封装了了非线程安全的Map,对所有读写方法都用synchronized加锁。
这样获得的线程安全集合的性能比java.util.concurrent集合要低很多,所以不推荐使用。
Atomic 类
Java的java.util.concurrent包除了提供底层锁、并发集合外,还提供了一组原子操作的封装类,它们位于java.util.concurrent.atomic包。
我们以AtomicInteger为例,它提供的主要操作有:
- 增加值并返回新值:
int addAndGet(int delta) - 加1后返回新值:
int incrementAndGet() - 获取当前值:
int get() - 用CAS方式设置:
int compareAndSet(int expect, int update)
Atomic类是通过无锁(lock-free)的方式实现的线程安全(thread-safe)访问。它的主要原理是利用了CAS:Compare and Set。
如果我们自己通过CAS编写incrementAndGet(),它大概长这样:
1 | // 可以把这里的 var 看成对象属性,参数(局部变量)在多线程中是不共享的。 |
CAS:将比较和写入封装成原子性操作。
用一个以 CAS 为条件的 do~while 循环包裹 inc 和 get 操作,只要在自增后原值不变则返回值,如果期间改变了就重复操作。
利用AtomicLong可以编写一个多线程安全的全局唯一ID生成器:
1 | class IdGenerator { |
在高度竞争的情况下,还可以使用Java 8提供的LongAdder和LongAccumulator。
应用:
- 原子操作实现了无锁的线程安全;
- 适用于计数器,累加器等。
线程池
为什么需要线程池?
因为创建线程需要操作系统资源(线程资源,栈空间等),频繁创建和销毁大量线程需要消耗大量时间。
而大多数情况下因为每个线程执行的任务不一定会同时完成,而是有一些线程提前完成。
那如果需要继续完成类似的任务,要继续创建新的线程来执行吗?
不是的,为了避免频繁创建线程浪费资源,选择创建一个线程池,当线程执行结束后,会被收回线程池,以供下次调用,就不用创建新线程了。
创建线程池
1 | import java.util.concurrent.*; |
提交任务后,会异步的执行完这一些任务。
线程池在程序结束的时候要关闭。有三种关闭的方式:
- 使用
shutdown()方法关闭线程池的时候,它会等待正在执行的任务先完成,然后再关闭。 shutdownNow()会立刻停止正在执行的任务,awaitTermination()则会等待指定的时间让线程池关闭。
因为ExecutorService只是接口,Java标准库提供的几个常用实现类有:
- FixedThreadPool:线程数固定的线程池;
- CachedThreadPool:线程数根据任务动态调整的线程池;
- SingleThreadExecutor:仅单线程执行的线程池。
创建这些线程池的方法都被封装到Executors这个工厂类中,可以选择创建需要的线程池。
ScheduledThreadPool
还有一种任务,需要定期反复执行,例如,每秒刷新证券价格。
这种任务本身固定,需要反复执行的,可以使用ScheduledThreadPool。
创建一个ScheduledThreadPool仍然是通过Executors类:
1 | ScheduledExecutorService ses = Executors.newScheduledThreadPool(4); |
我们可以提交一次性任务,它会在指定延迟后只执行一次:
1 | // 1秒后执行一次性任务: |
如果任务以固定的每3秒执行,我们可以这样写:
1 | // 2秒后开始执行定时任务,每3秒执行: |
如果任务以固定的3秒为间隔执行,我们可以这样写:
1 | // 2秒后开始执行定时任务,以3秒为间隔执行: |
注意FixedRate和FixedDelay的区别。FixedRate是指任务总是以固定时间间隔触发,不管任务执行多长时间:
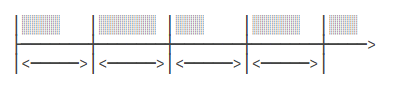
而FixedDelay是指,上一次任务执行完毕后,等待固定的时间间隔,再执行下一次任务:
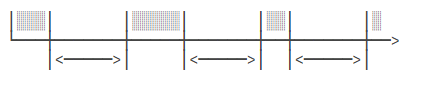
注意:
在FixedRate模式下,假设每秒触发,如果某次任务执行时间超过1秒,后续任务会不会并发执行?
也就是原定于每 1 秒执行一次的任务,但是上次任务还没有执行完,还会根据每秒一次执行吗?
答案:不会,如果任务执行时间超出了触发间隔,会在这一次任务执行完毕后,再执行下一次任务,如果下一次任务没有超出时间间隔,则保持间隔时间触发,如果又超出了,继续等待至完毕后再执行下一次,变成了顺序执行固定任务。
如果任务抛出了异常,后续任务是否继续执行?
答案:如果一个定时任务中任何一次执行出现了问题,这么这个 schedule 就会停止。
Timer
Java标准库还提供了一个java.util.Timer类,这个类也可以定期执行任务,但是,一个Timer会对应一个Thread,所以,一个Timer只能定期执行一个任务,多个定时任务必须启动多个Timer,而一个ScheduledThreadPool就可以调度多个定时任务,所以,我们完全可以用ScheduledThreadPool取代旧的Timer。
Future
Runnable接口有个问题,它的方法没有返回值。
如果任务需要一个返回结果,那么只能保存到变量,还要额外封装方法读取,要考虑诸多因素非常不便。
所以,Java标准库还提供了一个Callable接口,和Runnable接口比,它多了一个返回值:
1 | class Task implements Callable<String> { |
并且Callable接口是一个泛型接口,可以返回指定类型的结果。
在线程池中的 submit 中,如果提供一个 Callable 接口,就会返回一个Future类型,一个Future类型的实例代表一个未来能获取结果的对象:
1 | ExecutorService executor = Executors.newFixedThreadPool(4); |
在调用get()时,如果异步任务已经完成,我们就直接获得结果。
如果异步任务还没有完成,那么get()会阻塞,直到任务完成后才返回结果。
一个Future<V>接口表示一个未来可能会返回的结果,它定义的方法有:
get():获取结果(可能会等待)get(long timeout, TimeUnit unit):获取结果,但只等待指定的时间;cancel(boolean mayInterruptIfRunning):取消当前任务;isDone():判断任务是否已完成。
CompletableFuture
使用Future获得异步执行结果时,由于 get 结果并进行处理会进行阻塞或者封装一些其他的方法,非常麻烦。
从Java 8开始引入了CompletableFuture,它针对Future做了改进,可以传入回调对象,当异步任务完成或者发生异常时,自动调用回调对象的回调方法。
使用方法
1 | import java.util.concurrent.CompletableFuture; |
执行成功:thenAccept;执行异常:exceptionally。
supplyAsync接收的是一个Supplier接口函数,thenAccept, exceptionally接收一个Consumer接口函数
相比于 Future 优点:
- 异步任务结束时,会自动回调某个对象的方法;
- 异步任务出错时,会自动回调某个对象的方法;
- 主线程设置好回调后,不再关心异步任务的执行。
CompletableFuture 还可以制作串行、并行及两者结合的异步操作
串行
1 | public class Main { |
通过 thenApplyAsync 接着上一步异步继续执行,并且返回一个新的 CompletableFuture 对象。
并行串行结合
考虑如下这样的一个场景:
同时从新浪和网易查询证券代码,只要任意一个返回结果,就进行下一步查询价格,查询价格也同时从新浪和网易查询,只要任意一个返回结果,就完成操作:
1 | public class Main { |
上述的执行流程,可以用下图解释:
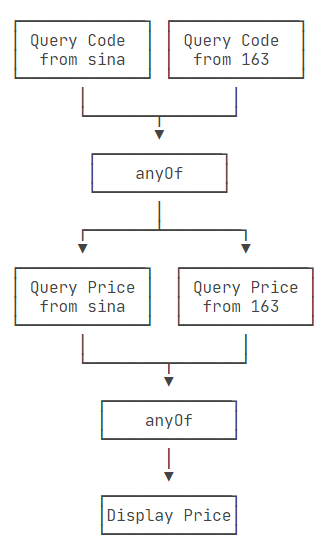
除了anyOf()可以实现“任意个CompletableFuture只要一个成功”,allOf()可以实现“所有CompletableFuture都必须成功”,这些组合操作可以实现非常复杂的异步流程控制。
最后我们注意CompletableFuture的命名规则:
xxx():表示该方法将继续在已有的线程中执行;xxxAsync():表示将异步在线程池中执行。
注意:不管是 thenApplyAsync 还是 anyOf, allOf 等操作对 CompletableFuture 进行整合,都会返回一个新的 CompletableFuture 对象,最终结果应基于最后一个组合对象操作。
还有个 runAsync 方法,可以不需要返回值也能使用。
ForkJoin
Java 7开始引入了一种新的Fork/Join线程池,它可以执行一种特殊的任务:把一个大任务拆成多个小任务并行执行。
以大数据进行并行求和为例:
1 | public class Main { |
观察上述代码的执行过程,一个大的计算任务02000首先分裂为两个小任务01000和10002000,这两个小任务仍然太大,继续分裂为更小的0500,5001000,10001500,1500~2000,最后,计算结果被依次合并,得到最终结果。
该例子并不适用,因为本质是同源的,多线程最大的优势是在应用不同源。
同源:每次切换一个线程加一点数,和一次加完所有的数是一样的(也不一定,多核CPU下,当然是一个任务能占据更多核速度最快)。
不同源:每次切换一个线程和不同“服务”通信,所有服务并行执行。
Fork/Join线程池在Java标准库中就有应用。
Java标准库提供的java.util.Arrays.parallelSort(array)可以进行并行排序,它的原理就是内部通过Fork/Join对大数组分拆进行并行排序,在多核CPU上就可以大大提高排序的速度。
ThreadLocal
多线程是Java实现多任务的基础。
获取多线程id
Thread对象代表一个线程,我们可以在代码中调用Thread.currentThread()获取当前线程。
传递状态
通常一个任务需要多个方法完成,对象如何在多个方法中传递相同的状态?
定义一个对象属性?多线程共享会不一致该怎么办?
Java标准库提供了一个特殊的ThreadLocal,它可以确保每一个线程中都维护各自的一个对象属性值。
ThreadLocal实例通常总是以静态字段初始化如下:
1 | static ThreadLocal<User> threadLocalUser = new ThreadLocal<>(); |
使用方式
1 | // 加载器 |
可以把ThreadLocal看成一个全局Map<Thread, Object>:每个线程获取ThreadLocal变量时,总是使用Thread自身作为key:
1 | Object threadLocalValue = threadLocalMap.get(Thread.currentThread()); |
因此,ThreadLocal相当于给每个线程都开辟了一个独立的存储空间,各个线程的ThreadLocal关联的实例互不干扰。
最后,特别注意ThreadLocal一定要在finally中清除:
1 | try { |
这是因为当前线程执行完相关代码后,很可能会被重新放入线程池中,如果ThreadLocal没有被清除,该线程执行其他代码时,会把上一次的状态带进去。
而且 ThreadLocal 可以维护的线程数是有限的,如果超出了限制,会造成内存污染,共用一个对象的情况。
实现 AutoCloseable 接口
为了保证能释放ThreadLocal关联的实例,我们可以通过AutoCloseable接口配合try (resource) {...}结构,让编译器自动为我们关闭。
例如,将用于保存当前用户名的ThreadLocal封装为一个UserContext对象:
1 | public class UserContext implements AutoCloseable { |
使用的时候,我们借助try (resource) {...}结构,可以这么写:
1 | try (var ctx = new UserContext("Bob")) { |
将 UserContext 实例对象的作用限定在 try {} 中,当离开作用域时自动回收该实例,并调用 close 方法移除 ThreadLocal 关联对象(有点像析构方法接口)。
网络编程
易混概念
- 主类: 所有定义了main方法的类叫做主类,开发者常在类中定义main方法,用来调试代码
- 在基本数据类型变量声明时,不能用占用内存大的值赋给占用内存小的变量类型,如 float a = 1.19; 1.19 默认是double型,因此该语句会编译出错; ==2e9==科学计数,默认也是double型!!!
- 使用…声明可变长参数,如int sort(int… a);
- 命令行参数
各个类的main方法可以相互调用
1 | class B { |
- 重载是==多态==的一种。
- 不管是继承还是实现接口,重写方法时都不可以降低方法的可见性(Visiability)
如:继承的public方法不能重写为protected方法,但是protected方法重写后可改为public。